论文
Practical Lessons from Predicting Clicks on Ads at Facebook
为什么读这篇
本文属于深度学习时代之前的一篇经典CTR点击率预估paper,即Facebook大名鼎鼎的GBDT+LR,在该模型之前主要使用UserCF、ItemCF。wide & deep等深度学习出现后,逐渐退出舞台了,不过为了夯实下基础,还是得看看,同时希望可以从历史经典中挖出什么一些新的点子。
背景介绍
14年的KDD,出自脸书,总共11个作者,有华人有老外,有趣的是在本文发表时各个作者就已经各奔东西了,去哪的都有,Square,Quora,Twitter,Amazon。一作Xinran He现在在Snap,本篇是他读博二时在Facebook实习的工作。90后,08年北大本科,12年南加州PHD。与作者同样是90后差距太大了。
摘要
Facebook的日活7.5亿,广告主1百万(14年)。本文提出的模型结合了决策树和逻辑回归(GBDT+LR)预测广告CTR(点击率),相比各自方法有3%的提升。也探索了一些基本参数是如何影响系统的最终预测性能。这会对整体系统的表现的提升产生重大影响。作者探索了一些基础参数怎么影响系统的最终预测表现。不出意外的是,最重要的事情是拥有正确的特征:捕获到的用户和广告的历史信息支配着其他类型的特征。一旦我们有了正确的特征和正确的模型(决策树加逻辑回归),其他的因素就影响很小(虽然小的改进在规模上很重要)。选择对数据新鲜度,学习率模式,和数据采样的最佳处理能够轻微的改变模型,但远不如一开始就选择高价值的特征或选择正确的模型。
简而言之,文章提出了一种利用GBDT自动进行特征筛选和组合,进而生成新的feature vector,再把该feature vector当作logistic regression的模型输入,预测CTR的模型结构。
1. 介绍
数字广告是一个数十亿美元规模的产业,并且逐年高速增长。大多数在线广告平台的广告投放是动态调整的,并基于观测用户反馈的兴趣进行定制的。机器学习在计算候选广告对用户的期望效用上起到主要作用,并以此提高市场效率。
Varian和Edelman等人于2007年发表的有影响力的论文描述了由Google和Yahoo开创的按点击次数出价和付费的拍卖模型。同一年,微软也基于同样的拍卖模型(auction model)搭建了赞助搜索市场。广告拍卖的效率依赖于点击预测的精度和校准(calibration)。点击预测系统必须具有稳健性和适应性,并且能够胜任从海量数据中学习。本文的目标是分享从实验及真实应用中获得的见解。
在赞助搜索广告中,用户查询(query)用于检索和查询匹配的候选广告。在Facebook,广告不是和查询关联,而是通过人口统计(specify demographic)和兴趣确定目标,因此用户访问Facebook时符合展示的广告量比赞助搜索更大。
用户访问Facebook会触发广告请求,而每次广告请求需要处理大量的候选广告,所以我们构建了计算成本逐级升高的级联分类器。本文重点介绍最后一个阶段的点击预测模型。
这篇论文的目的就是分享用真实世界的数据,并且具有鲁棒性和适应性的实验中得到的见解。
Facebook由于其特殊性,不能使用搜索记录进行广告推荐,而是基于对用户的定位,所以可展示广告的量也更多。Facebook为此建立的级联分类器。这篇文章专注于级联分类器的最后一个阶段点击预测模型,就是这个模型对最终的候选广告集的广告进行预测是否会被点击。
级联分类器
级联是基于几个分类器的串联的集合学习的特定情况,使用从给定分类器的输出收集的所有信息作为级联中的下一个分类器的附加信息。与投票或堆叠合奏(多专家系统)不同,级联是多阶段的。
2. 实验
2.1 构建training data和testing data
为了实现严格可控的实验,我们选择2013年第四季度任意一周的数据作为离线训练数据。为了保持不同条件下训练数据和测试数据的一致性,准备的离线训练数据要和在线观测的数据相似。我们将存储的离线数据分割成训练数据和测试数据,并使用它们模拟用于在线训练和预测的流数据。
2.2 评估指标Evaluation metrics:
由于我们最关注最重要的因素对机器学习模型的影响,因此我们使用预测的准确性,而不是直接与利润和收入相关的指标。在这项工作中,我们使用归一化熵(NE)和校准作为我们的主要评估指标。
2.2.1 Normalized Entropy(NE):
Normalized Entropy归一化熵的定义为每次展现时预测得到的log loss的平均值,除以对整个数据集的平均log loss值。之所以需要除以整个数据集的平均log loss值,是因为backgroud CTR(背景点击率是训练数据集的平均经验点击率)越接近于0或1,则越容易预测取得较好的log loss值,而做了normalization后,NE便会对backgroud CTR不敏感了。
NE在计算相关的信息增益时是至关重要的。上面是逻辑回归的损失函数,也就是交叉熵。下面是个常数,所以这个Normalized Entropy值越低,则说明预测的效果越好。下面列出表达式:
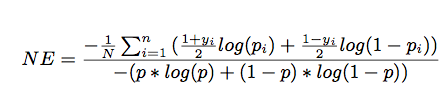
其中N是训练数据集样本数,标签yi取值为-1或+1,pi是预估点击概率,p是平均经验CTR(即广告实际点击次数除以广告展示量)。
NE本质上是计算相对信息增益(RIG)的一个组成部分,RIG = 1 - NE
2.2.2 Calibration校正:
Calibration定义为平均预估CTR(the average estimated CTR)和经验CTR(empirical CTR)的比率,即期望的点击数和实际观测的点击数的比率。Calibration 是一个很重要的指标,因为CTR的精确性和校准对在线出价和拍卖的成功至关重要。 该值越接近于1,模型效果越好。
AUC
注意,ROC下面积(AUC)也是衡量排序质量(不考虑校准)的一个很好的指标。在现实的环境中,我们希望该预测是准确的,而不是仅仅获得最佳排名,以避免潜在的广告投放不足或广告投放过多。 NE可以衡量预测的良好性,并直接反映校准。例如,如果一个模型高估了2倍,并且我们应用了一个全局乘数0.5来修改校准,那么即使AUC保持不变,相应的NE也将得到改善。
上面那句话的意思是NE衡量预测的良好性反应校准,AUC衡量排名质量而不考虑校准。
因为我们需要利用CTR计算精准的出价、ROI等重要的后续预估值,因此CTR模型的预估值需要是一个具有物理意义的精准的CTR,而不是仅仅输出广告排序的高低关系。所以文中不仅把CTR calibration作为重要的评价指标,更是在最后介绍了模型校正的相关方法。
3. 预测模型结构
本节评估不同的概率线性分类器和不同的在线学习算法。
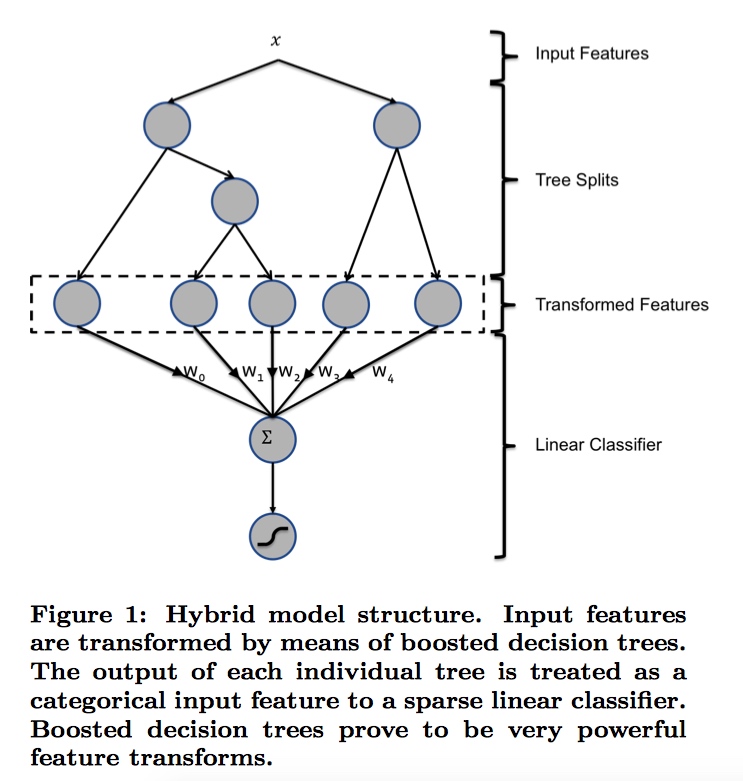
本节提出一种混合模型结构:提升决策树和概率稀疏线性分类器的串联。,如下图所示。
3.1节说明了决策树是非常强大的输入特征转换器,能够显著提升概率线性模型的精确度。
3.2节说明了更新鲜的训练数据能够使预测更精确,从而激发了一个想法:使用在线学习方法训练学习器。
3.3节比较了两种线性分类器的几个变体。
学习算法是用的是Stochastic Gradient Descent(SGD)随机梯度下降,或者Bayesian online learning scheme for probit regression(BOPR)贝叶斯概率回归在线学习方案都可以。本文评估的在线学习方案基于应用于稀疏线性分类器的SGD算法,原因是资源消耗要小一些。在特征变换后,曝光的广告是以结构化向量的形式给出的: ,其中
,其中 是第i个单元向量,而
是第i个单元向量,而 是n个分类输入特征的值。在训练阶段,假设给定二元标签
是n个分类输入特征的值。在训练阶段,假设给定二元标签 来表示点击或非点击。
来表示点击或非点击。
给定带标签的曝光广告 ,定义有效权重的线性组合定义为公式2:
,定义有效权重的线性组合定义为公式2:

其中 为线性点击分的权重向量。
为线性点击分的权重向量。
在SOTA的BOPR(Bayesian online learning scheme for probit regression)算法中,似然度和概率如下定义:

其中 为标准正态分布的累积密度函数,
为标准正态分布的累积密度函数, 为标准正态分布的密度函数。通过期望传播和矩匹配来实现在线训练。结果模型由权重向量的近似后验分布的均值和方差组成。
为标准正态分布的密度函数。通过期望传播和矩匹配来实现在线训练。结果模型由权重向量的近似后验分布的均值和方差组成。
本文比较了BOPR与似然函数的SGD, 。产生的算法通常称之为逻辑回归(LR)。
。产生的算法通常称之为逻辑回归(LR)。
SGD和BOPR都可以针对单个样本进行训练,所以他们可以做成流式的学习器(stream learner)。
3.1 决策树特征转换
有两种简单的特征变换方法。对于连续特征,第一种学习非线性变换的trick是将特征分箱,并将箱的索引视为分类特征。线性学习器有效地学习了该特征的分段常数非线性映射。学习有用的分箱边界是非常重要的,有许多信息最大化的方法可以实现这一点。第二个简单且有效的变换在于构建输入特征元组。但不是所有的组合都有用,没有用的可以修剪掉。
本文发现boosted决策树是一种强大且方便的方法,可以实现上面描述的那种非线性变换和元组变换。将每棵树视为一种分类特征,以实例最终落入的叶子的索引为值。使用1-of-k来编码这种类型的特征,那么我们把该叶子节点置为1,其他叶子节点置为0,所有叶子节点组成的向量即形成了该棵树的特征向量,把GBDT所有子树的特征向量concatenate起来,即形成了后续LR输入的特征向量。。举个栗子,如图1所示有两颗子树,第一颗子树有3个叶子,第二颗有2个叶子。如果一个实例最终落在第一颗子树的第二个叶子上,第二颗子树的第一个叶子上,则整个输入变为二元向量 [0, 1, 0, 1, 0]。其中前3个节点对应第一颗子树的叶子节点,后两个对应第二颗子树。
本文使用GBM(Gradient Boosting Machine梯度提升机),经典的L2-TreeBoost算法。在每次学习迭代中,都会创建一棵树来对之前的树的残差进行建模。我们可以将基于boosted决策树的变换理解为一种有监督的特征编码,它将实数型向量转换为紧凑的二元向量。从根节点到叶子节点的遍历,表示某些特征的规则。在二元向量上拟合线性分类器,本质上就是学习规则集的权重。boosted决策树以批处理的方式进行训练。
GBDT是由多棵回归树组成的树林,后一棵树利用前面树林的结果与真实结果的残差做为拟合目标。每棵树生成的过程是一棵标准的回归树生成过程,因此每个节点的分裂是一个自然的特征选择的过程,而多层节点的结构自然进行了有效的特征组合,也就非常高效的解决了过去非常棘手的特征选择和特征组合的问题。
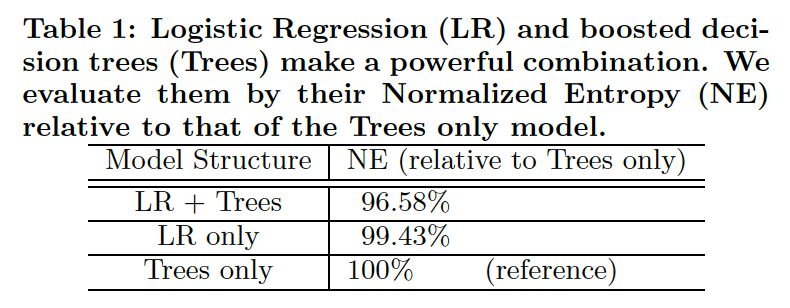
实验效果如表1所示,这里记得NE值越低表示模型越好。有了树特征变换的方法,有了相对3.4%的提升。作为对比,大多数特征工程的实验只能提升一个百分点。
3.2 数据新鲜度
点击预测系统通常部署在动态环境中,数据分布会随时间变化。
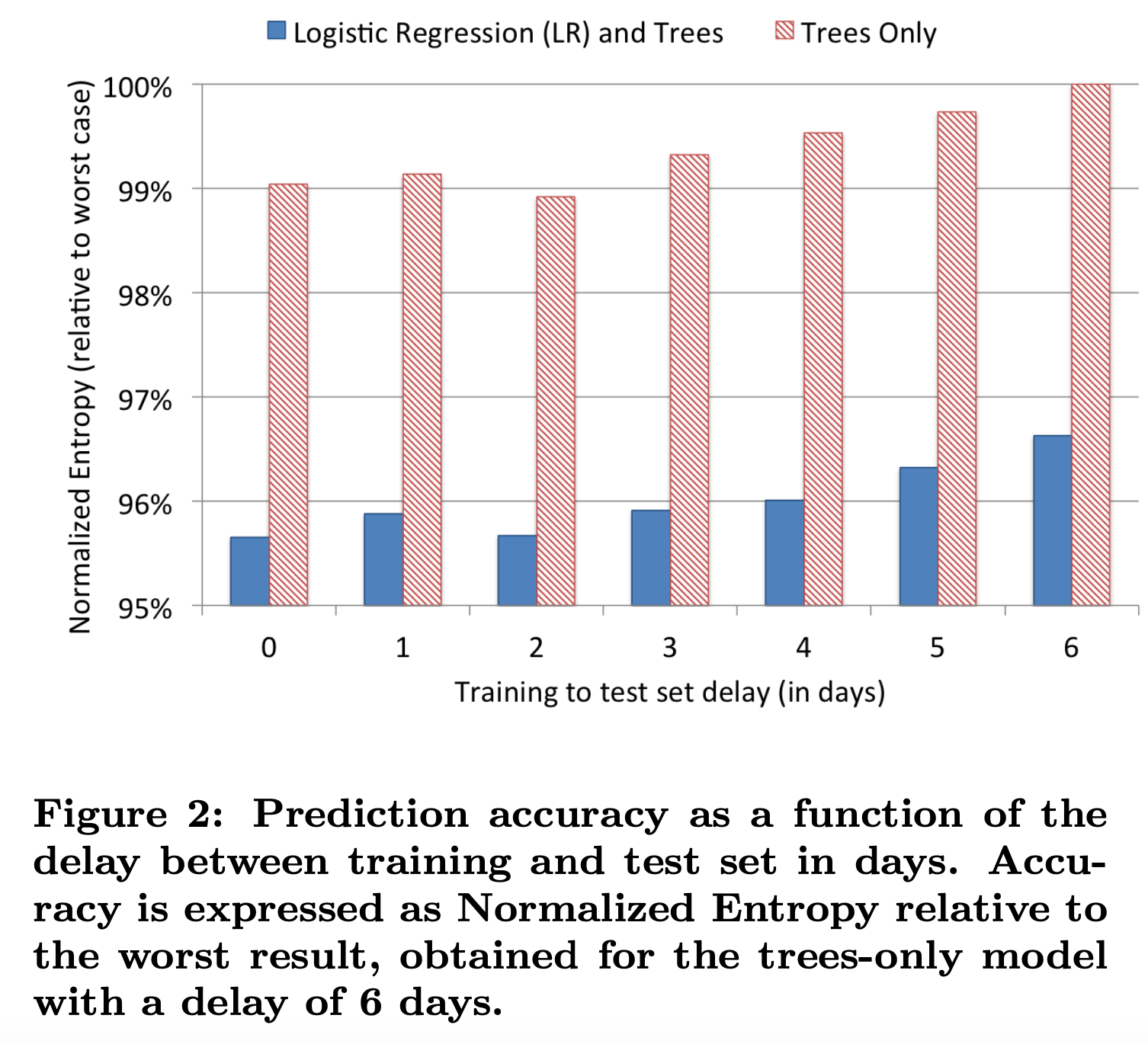
如图2所示,随着训练集合测试集延迟的增加,两种模型的预测准确率明显降低。使用单核CPU,上亿的实例,数百颗树来构建boosting模型可能需要24小时以上。在实际情况下,在一个多核机器上,通过足够的并发性,在几个小时内就可以完成训练,而多核机器要有足够的内存来保存整个数据集。在下一节会考虑另一种替代方案,gbdt可以天级训练,而线性分类器可以通过一些在线学习实现近实时训练。
3.3 在线线性分类器
为了最大程度的提高数据的新鲜度,一种方法是在线训练线性分类器,即将带有标签的曝光广告到达时就进行训练。在第4节描述了一个可以生成实时训练数据的基础架构。在本节评估几种基于SGD的在线学习的逻辑回归的学习率设置方法。这里给出了5种学习率设置方法,前三种是每个特征的学习率是独立的,后两种是对所有特征使用相同的学习率。通过网格搜索的最佳学习率如表2所示:
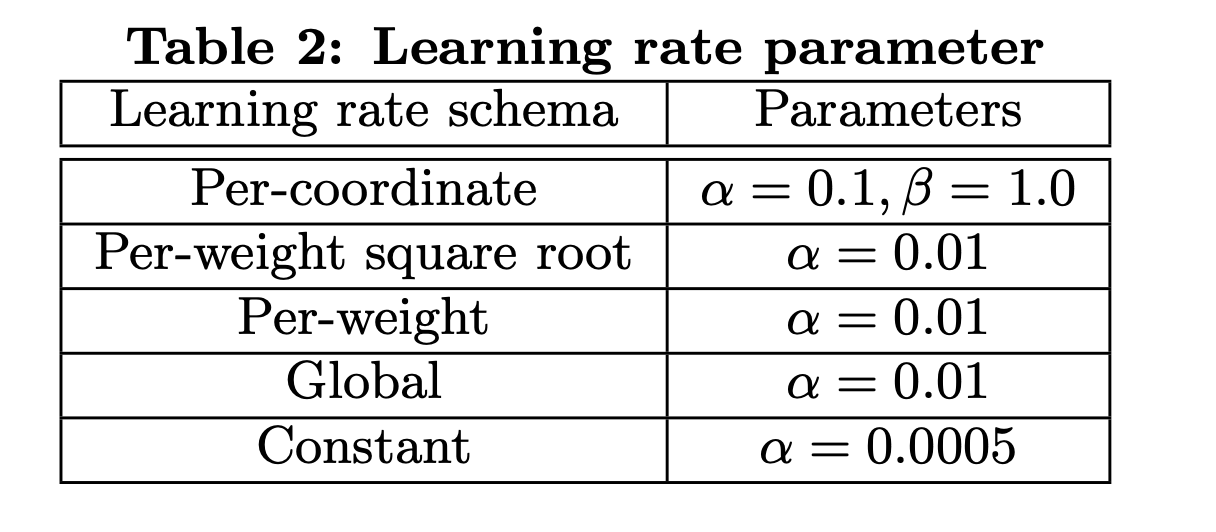
实验结果如图3所示:
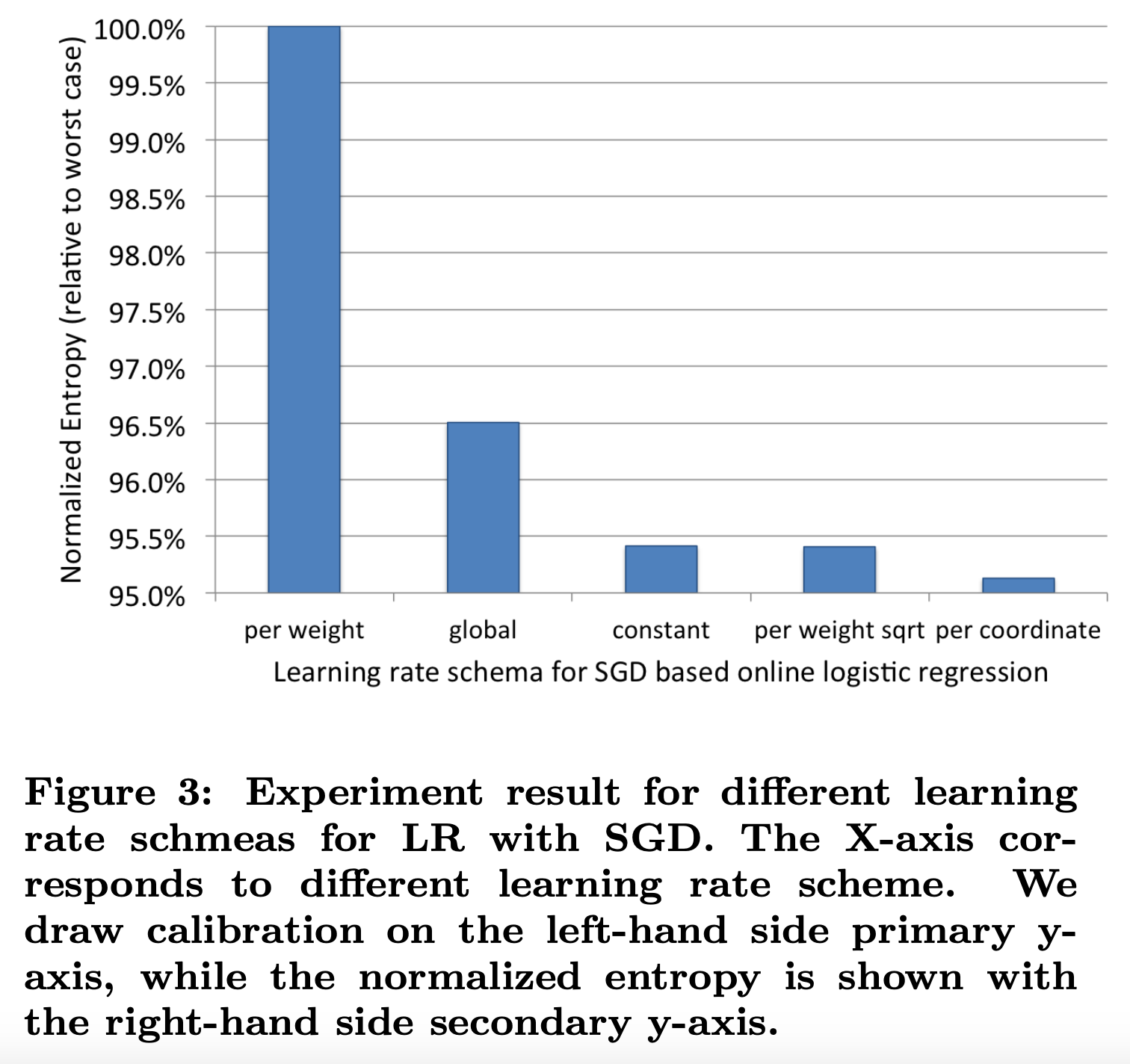
per coordinate的效果最好(也就是FTRL),相比per weight有5%的提升。
LR和BOPR的对比如表3所示:
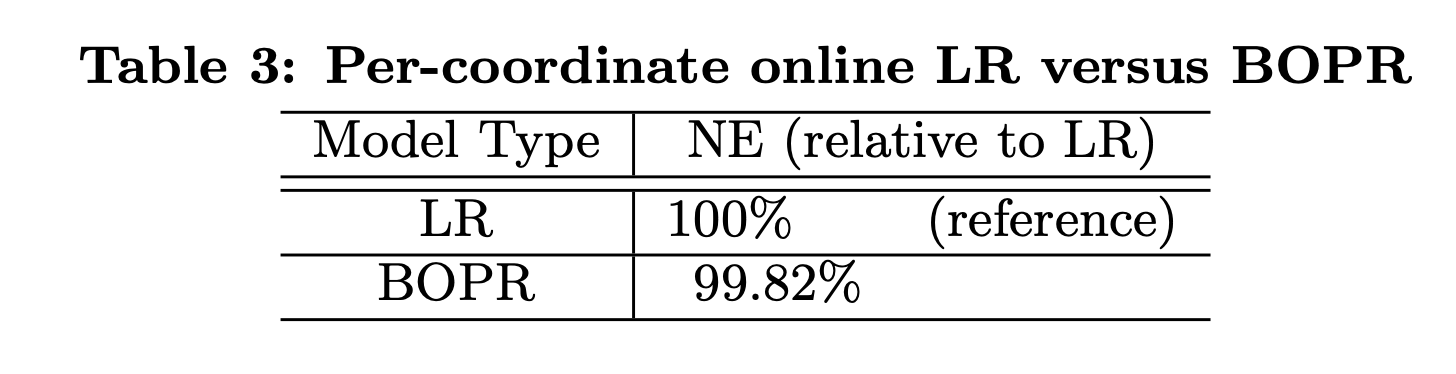
两者效果差不多,但LR相比BOPR的优势在于模型大小只有一半。BOPR相比LR的优势在于可以进行explore/exploit(探索/利用)。
4. 在线数据连接器
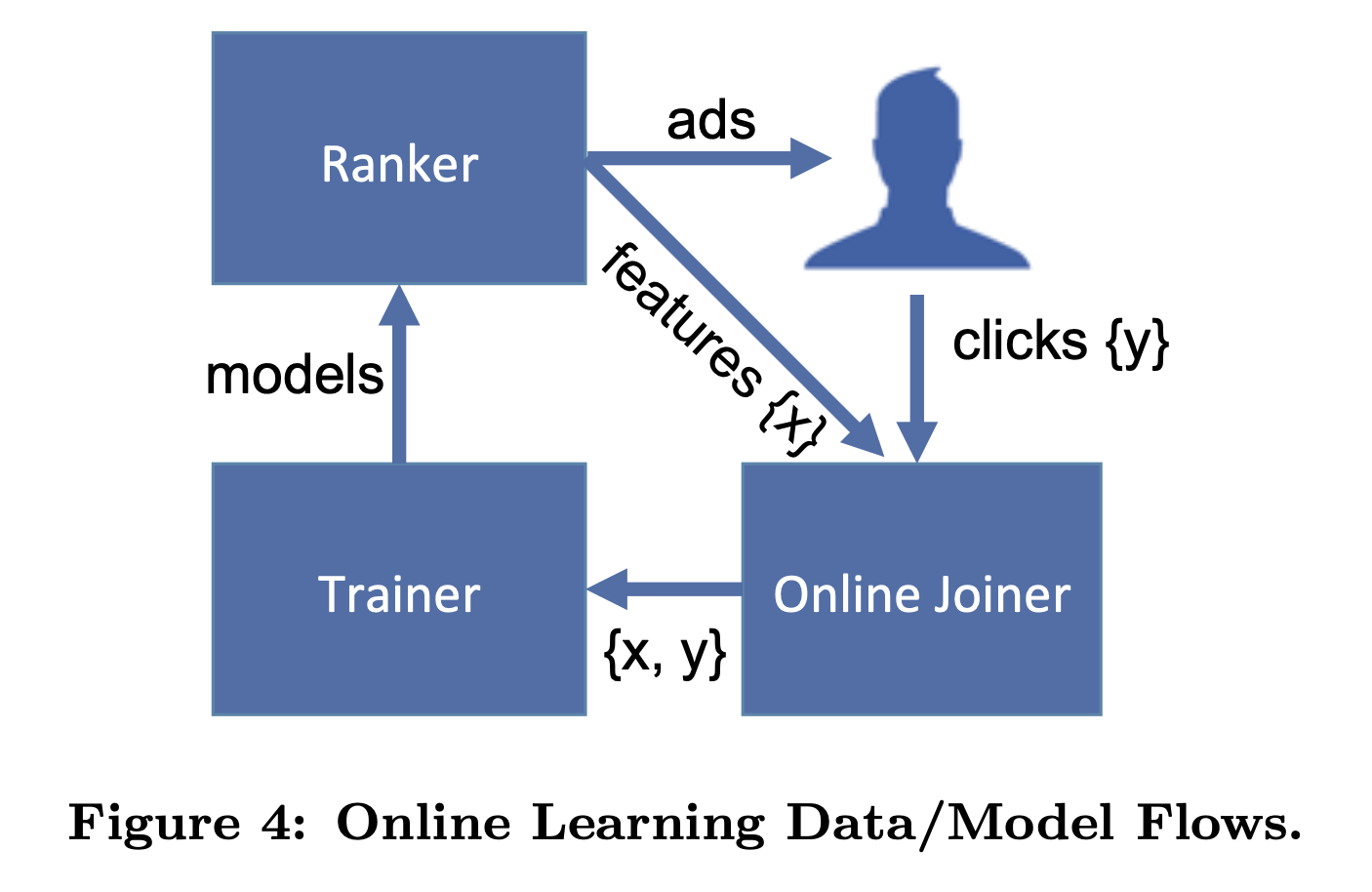
本文将这个系统称为“在线连接器”(online data joiner),因为它的关键操作是将标签(点击/不点击)与训练输入(广告曝光)以在线的方式连接在一起,类似的基础架构也用于流式学习,例如google的广告系统Photon。在线连接器将实时训练数据流输出到称为scribe的基础架构中。
- waiting window的设定: 非点击行为的确认需要等待,等待时间窗口的长度需要仔细调整。等待时间太长会造成实时训练数据的延迟,同时增加等待点击信号的曝光缓冲区内存的增加。窗口时间太短会导致一些点击丢失。这种负面效应称为“点击覆盖”,即成功连接曝光的点击比例。在线连接器系统必须在实时性和点击覆盖间取得平衡。
示意数据和模型流程如图4所示
-
分布式的架构与全局统一的action id: 为了实现分布式架构下impression记录和click记录的join,facebook除了为每个action建立全局统一的request id外,还建立了HashQueue缓存impressions。hashQueue缓存的impression,如果在窗口过期时还没有匹配到click就会当作negative sample,这里说的窗口与上面提到的waiting window相匹配。facebook使用scribe实现了这一过程,更多公司使用Kafka完成大数据缓存和流处理。
-
数据流保护机制: facebook专门提到了online data joiner的保护机制,因为一旦data joiner失效,比如click stream无法join impression stream,那么所有的样本都会成为负样本,由于模型实时进行online learning和serving,模型准确度将立刻受到错误样本数据的影响,进而直接影响广告投放和公司利润,后果是非常严重的。为此,facebook专门设立了异常检测机制,一旦发现实时样本数据流的分布发生变化,将立即切断online learning的过程,防止预测模型受到影响。
5. 内存和延迟的均衡
5.1 boosting tree个数
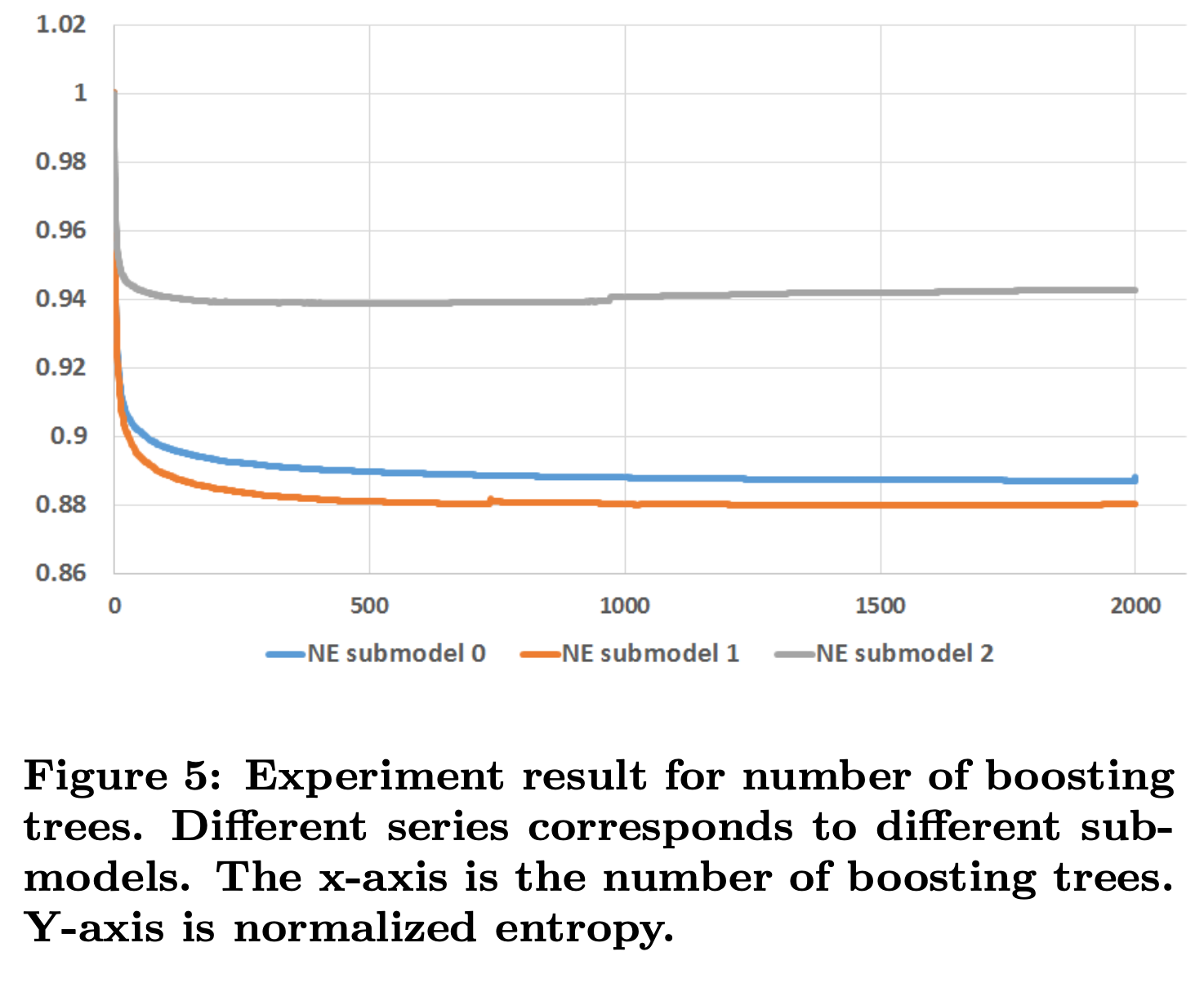
实验从1颗树到2000颗树,限制每颗树不超过12个叶子节点。从图5可以看到,几乎所有的提升都是来自前500颗树。
5.2 Boosting特征重要性
通常,少数特征贡献了绝大部分的解释力,而其余特征的贡献很小。如图6所示。
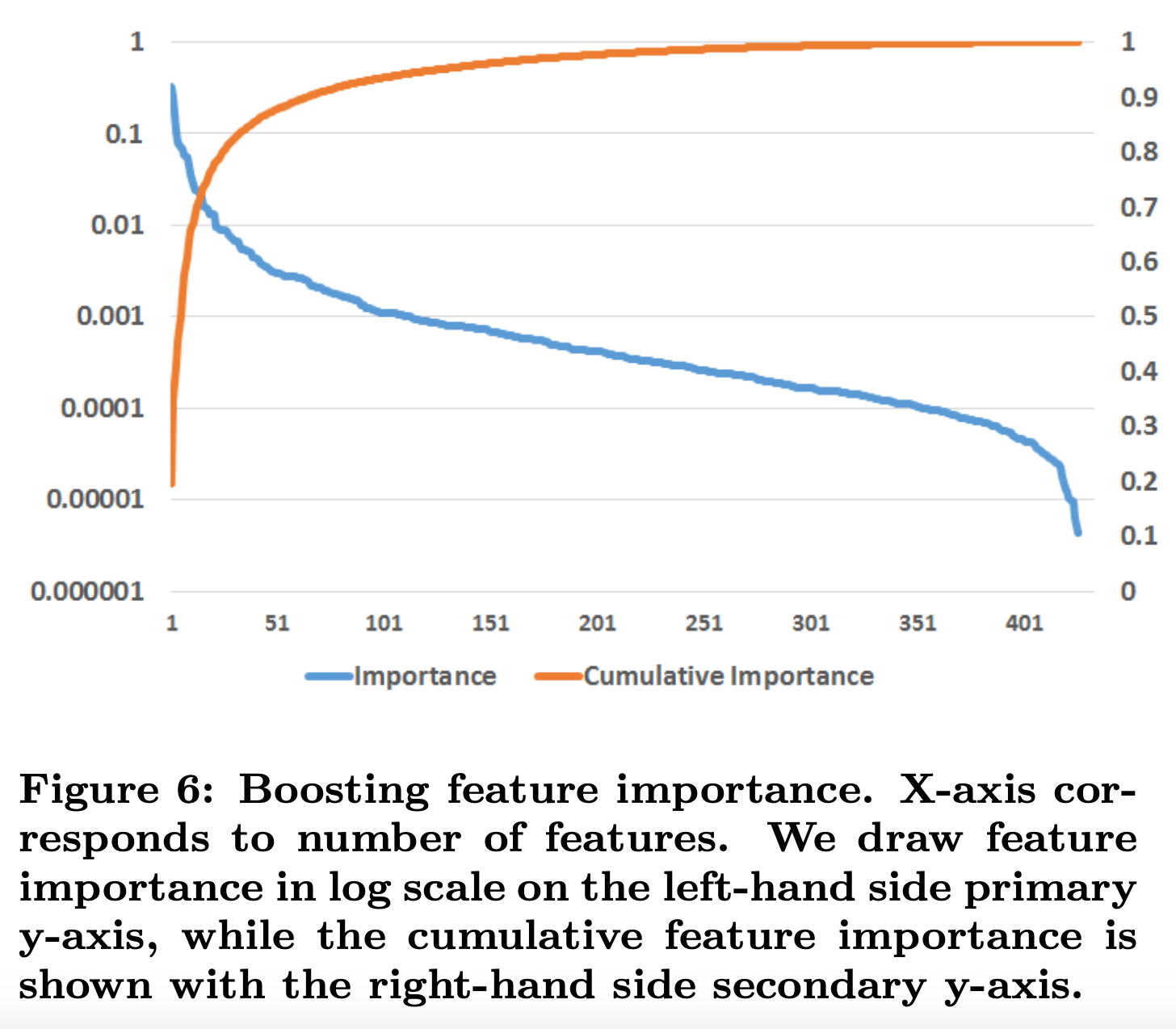
从上图可以看到,top10的特征贡献了一半的特征重要性,最后300个特征贡献了不到1%的特征重要性。
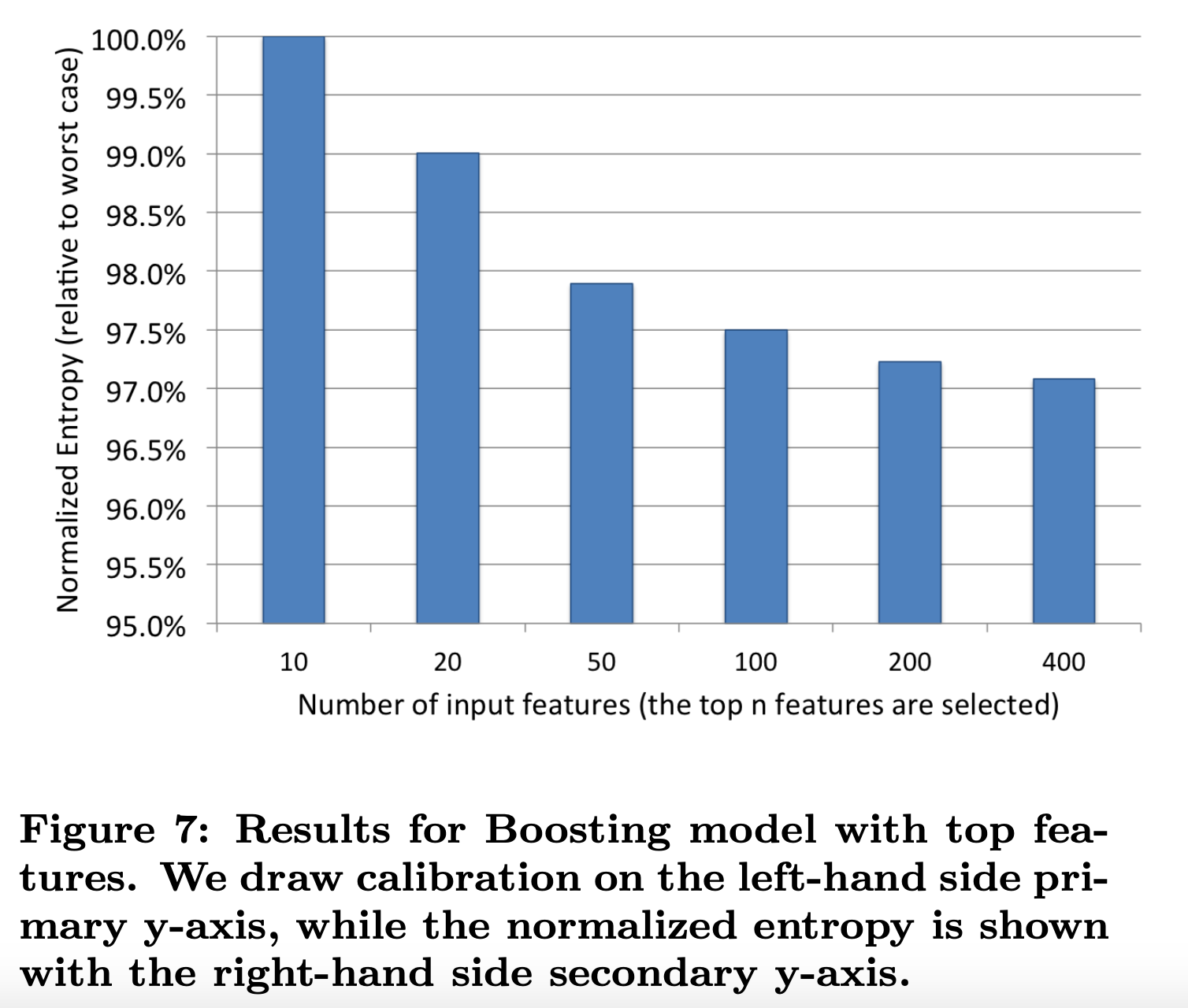
如图7所示实验了不同特征个数对模型效果的影响。
5.3 历史特征
在Boosting模型中使用的特征可以分为两类:上下文特征和历史特征。图8展示了历史特征在重要性中的占比。
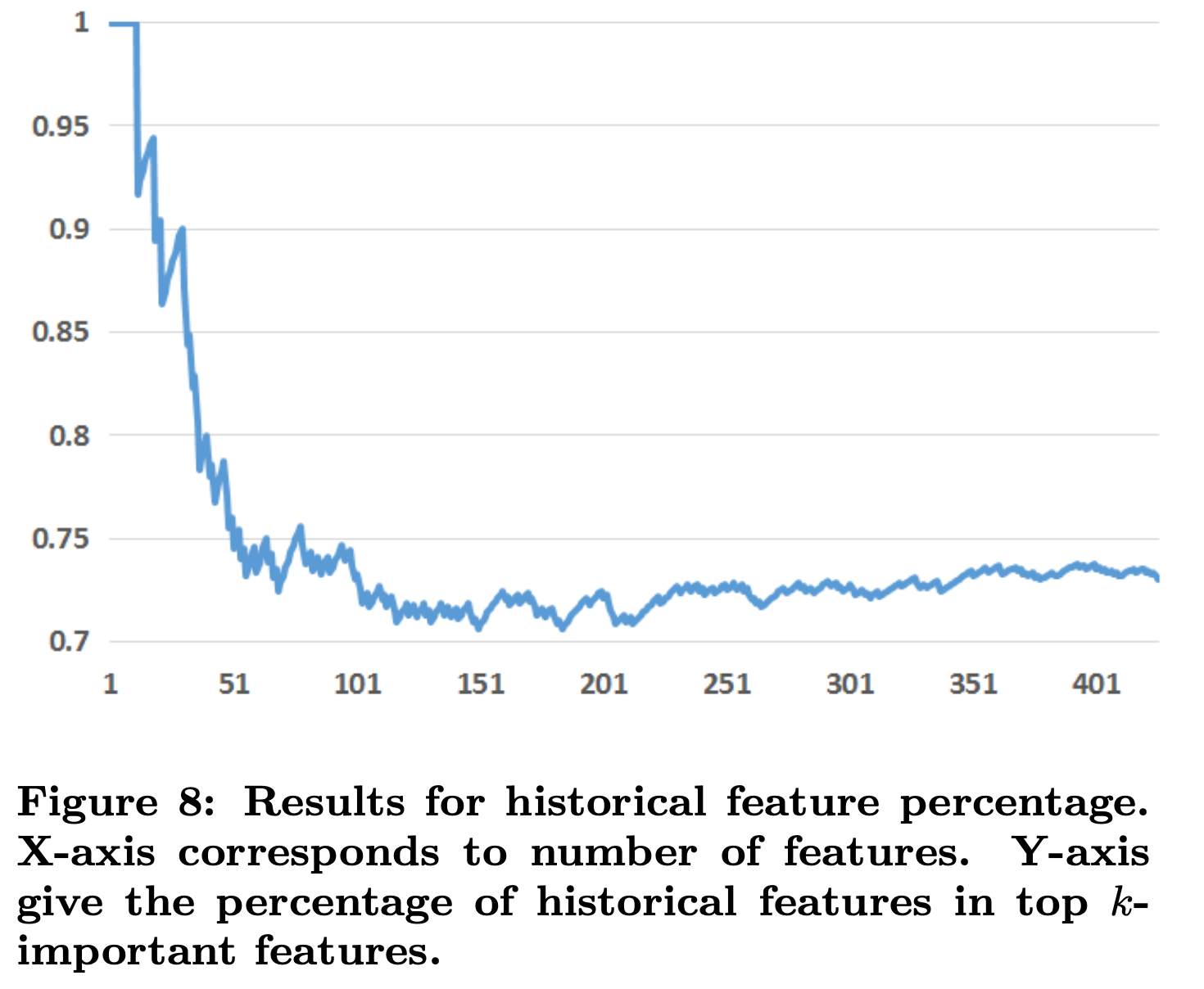
从上图可以看到,历史特征比上下文特征提供了更多的解释力。top10特征全是历史特征。表4展示了只用历史特征和只用上下文特征的效果。
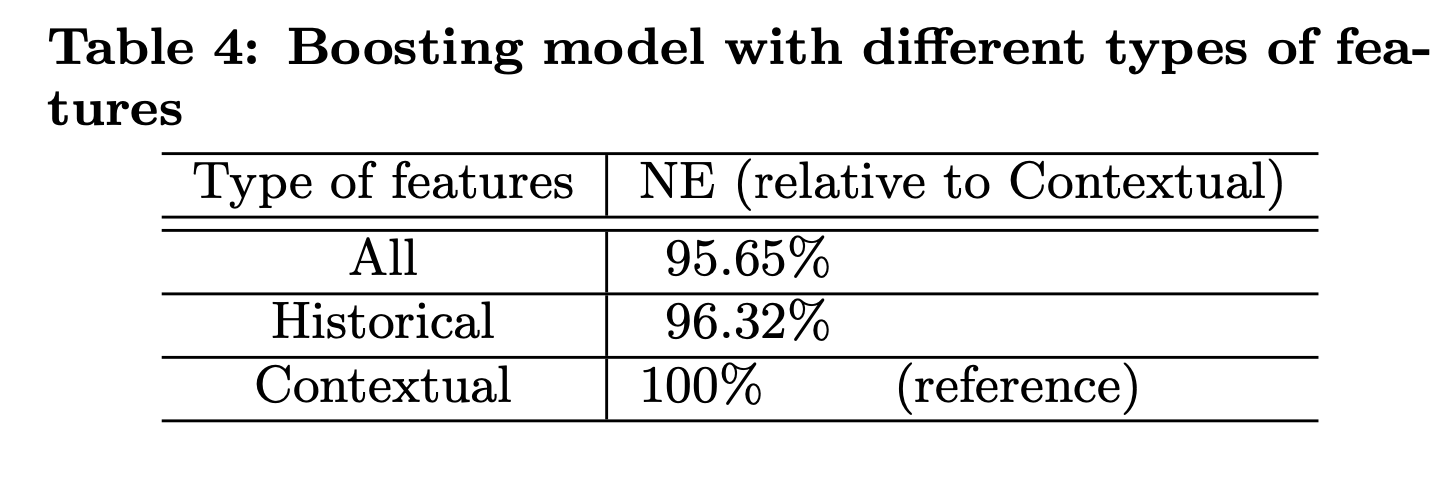
但是要主要上下文特征对于处理冷启动问题非常重要。
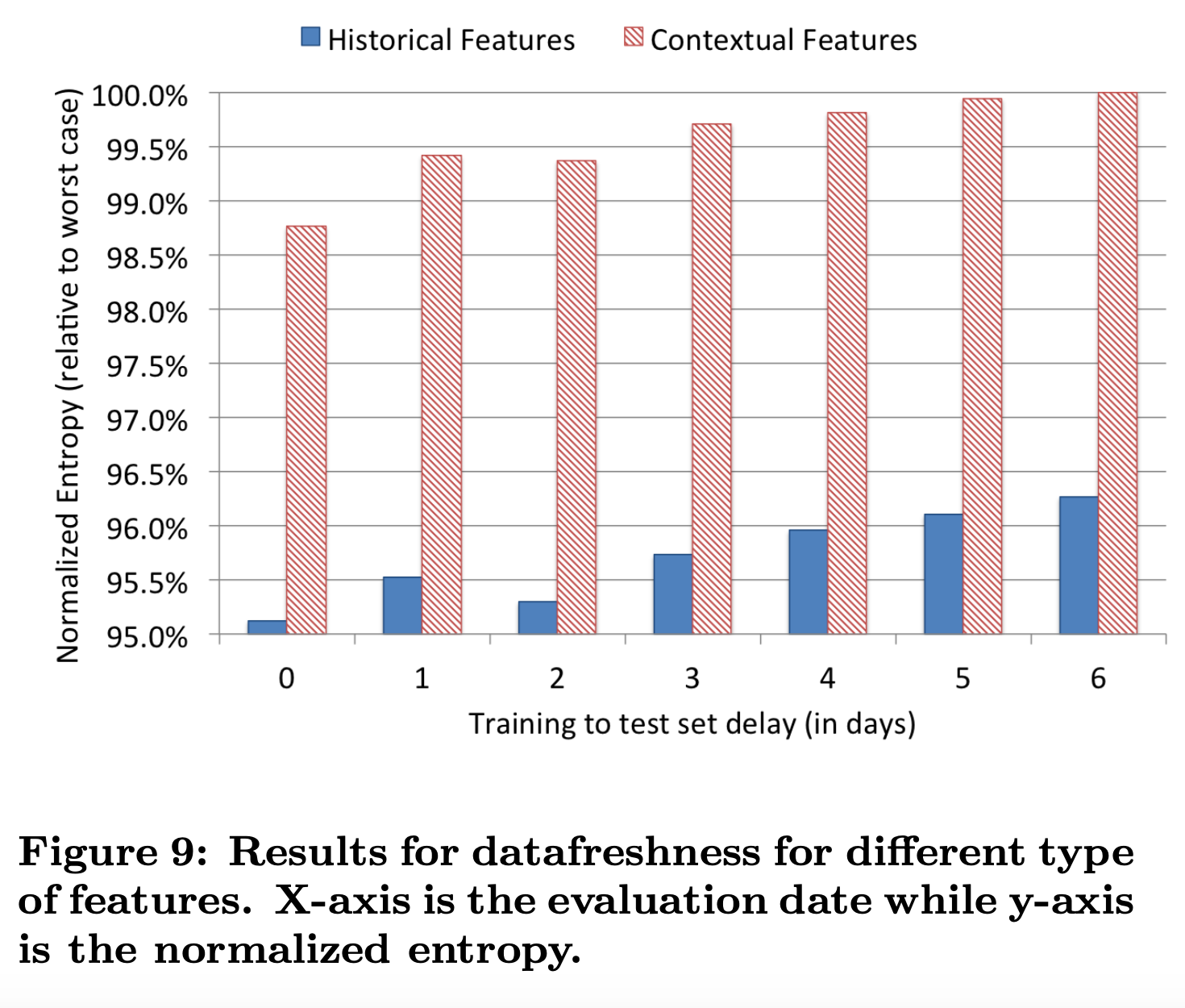
从图9可以看到,上下文特征相比历史特征更依赖数据新鲜度。
6. 应对海量训练数据
本节评估两种降采样技术,均匀降采样(Uniform subsampling)和负样本降采样(Negative down sampling)。
6.1 均匀降采样
均匀降采样(uniform subsampling)是对所有样本进行无差别的随机抽样,为选取最优的采样频率,facebook试验了0.001,0.01, 0.1, 0.5 和1五个采样频率,loss的比较如下:
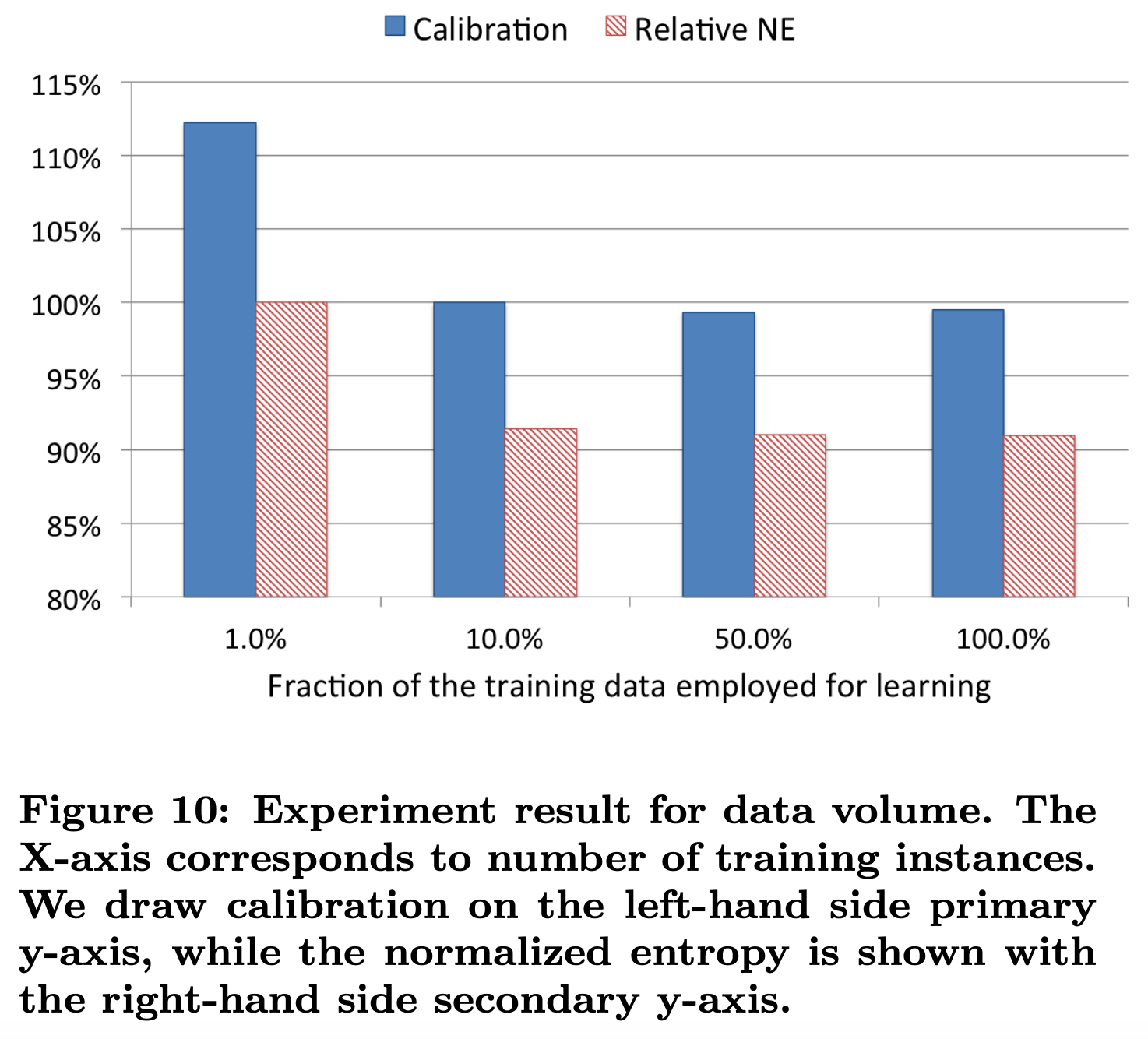
可以看到当采样率是10%时,相比全量数据训练的模型,仅损失了不到1%的效果。
6.2 负样本降采样
负样本降采样(negative down sampling)保留全量正样本,对负样本进行降采样。除了提高训练效率外,负采样还直接解决了正负样本不均衡的问题,facebook经验性的选择了从0.0001到0.1的一组负采样频率,试验效果如下:
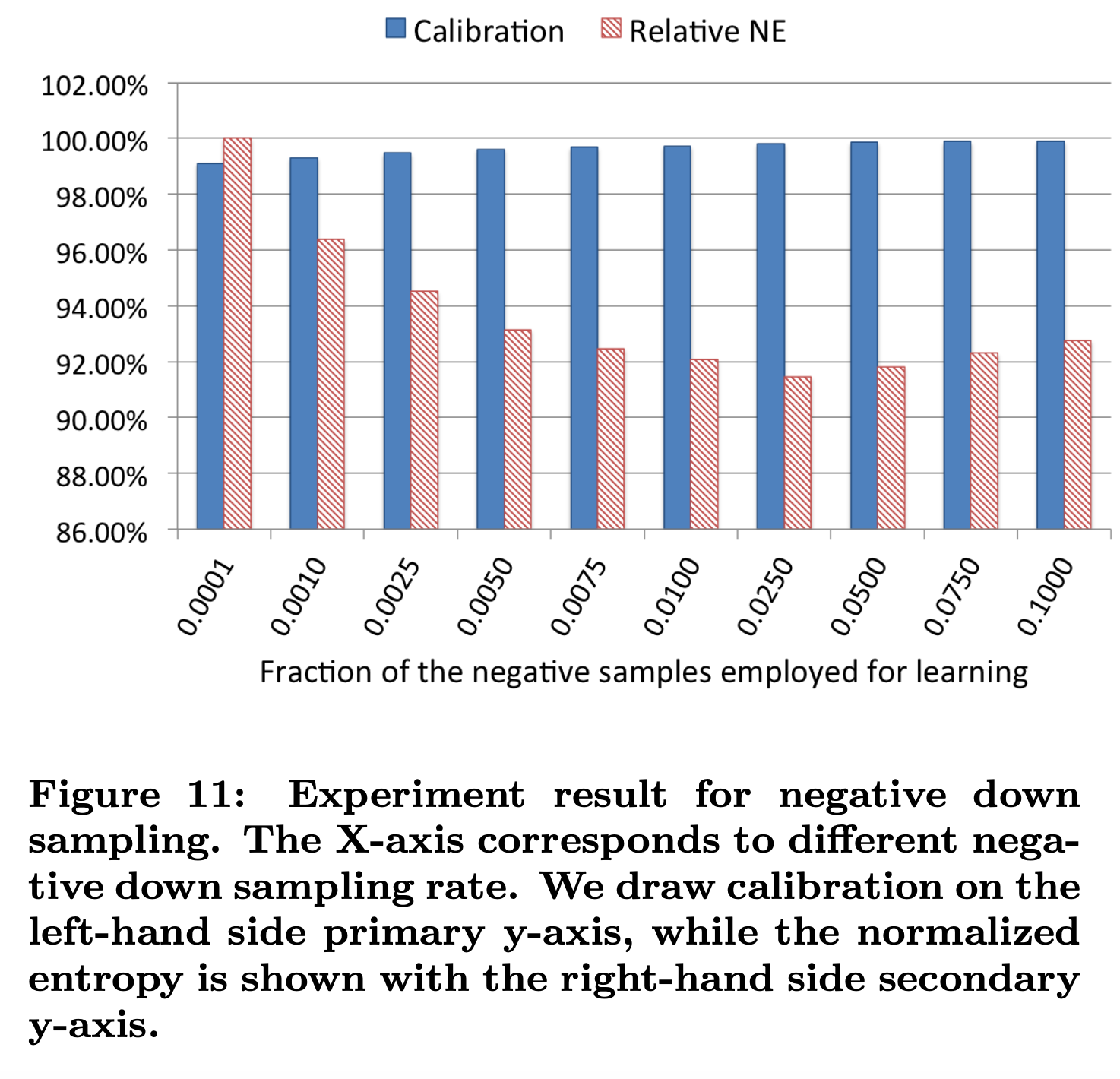
大家可以看到,当负采样频率在0.025时,loss不仅优于更低的采样频率训练出来的模型,居然也优于负采样频率在0.1时训练出的模型,虽然原文没有作出进一步的解释,但推测最可能的原因是解决了数据不均衡问题带来的效果提升。
6.3 模型重校正
负样本降采样能加速训练,同时提升模型性能。需要注意的是,如果模型用了负采样,那么也需要对降采样空间中的预测进行校准。这里举个例子,比如真实CTR是0.1%,进行0.01的负采样之后,CTR将会攀升到10%左右。而为了进行准确的竞价以及ROI预估等,CTR预估模型是要提供准确的有物理意义的CTR值的,因此在进行负采样后需要进行CTR的校正,使CTR模型的预估值的期望回到0.1%。

p为降采样空间中的预测,w为降采样比率,q为校准后的预测。
7. 结论
Facebook提出的LR + GBDT来提取非线性特征进行特征组合的方式非常经典,主要特性总结如下:
- Data Freshness很重要。模型至少一天重新训练一次是值得的,LR可以近乎实时的训练,但是数百颗树来构建boosting模型在多核机器也需要几个小时比较慢
- 使用Boosted Decision Tree转换实时输入特征很大程度上提高了线性分类器的预测准确率,这激发了将Boosted Decision Tree与稀疏的线性分类器(a sparse linear classifier)结合的混合模型架构。
- 最好的在线学习方法:LR + per-coordinate learning rate(基于SGD),该方法最终在性能上与BOPR相当,并且比所有其他正在研究的LR SGD方案表现更好。
关于平衡计算开销和模型性能所采用的技巧:
- 我们已经提出了Boosted decision trees的数量和准确性之间的权衡。保持树的数量少以保持计算和内存的存储是有利的。
- Boosted decision trees提供了通过特征重要性进行特征选择的便捷方法。人们可以去掉部分重要性低的特征,而仅适度地损害预测准确性。
- 我们分析了组合历史特征和上下文特征的。对于具有历史记录的广告和用户,历史特征提供的预测性能要优于上下文功能。
最后,我们讨论了对训练数据进行下采样的方法,这些数据都可以用均匀降采样,但是对带有偏置(bias)的负样本降采样更感兴趣
问题
1. GBDT建树细节
1) 为什么建树采用ensemble决策树?
一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。按paper以及Kaggle竞赛中的GBDT+LR融合方式,多棵树正好满足LR每条训练样本可以通过GBDT映射成多个特征的需求。
2) 为什么建树采用GBDT而非RF?
RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
然而,Facebook和Kaggle竞赛的思路是否能直接满足现在CTR预估场景呢?
按照Facebook、Kaggle竞赛的思路,不加入广告侧的Ad ID特征?但是现CTR预估中,Ad ID类特征是很重要的特征,故建树时需要考虑Ad ID。直接将Ad ID加入到建树的feature中?但是Ad ID过多,直接将Ad ID作为feature进行建树不可行。下面将介绍针对现有CTR预估场景GBDT+LR的融合方案。
参考
- 简书 论文笔记 KDD2014 Practical Lessons from Predicting Clicks on Ads at Facebook
- 知乎 王喆:回顾Facebook经典CTR预估模型
- 腾讯云社区 论文翻译 Practical Lessons from Predicting Clicks on Ads at Facebook
- zdkswd.github.io Practical Lessons from Predicting Clicks on Ads at Facebook
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!