1. 介绍
决策树是一个树结构(可以是二叉树或非二叉树),适用于分类和回归。决策树算法包括特征选择、决策树构建、决策树剪枝。
优点:模型具有可读性,分类速度快 缺点:容易过拟合,学习决策树是NP难题,数据集不平衡容易导致树模型产生偏差 实际使用技巧:
- 对于拥有大量特征的数据决策树会出现过拟合的现象。获得一个合适的样本比例的特征十分重要,因为在高维空间只有少量的样本的树是十分容易过拟合的。
- 考虑事先进行降维,使树更好的找到具有分辨性的特征
- 为防止决策树偏向主导类,可以通过从每个类中抽取相等数量的样本来进行类平衡
决策树算法包括特征选择、决策树构建、决策树剪枝。
2. 熵
2.1 信息熵
熵表示随机变量不确定性的度量 设X是一个有限状态的离散型随机变量,其概率分布为:
\[P(X = x_i) = p_i,\ i=1,2,\cdots,n\]则随机变量X的熵定义为
\[H(Y|X) = \sum_{i=1}^{n}p_i H(Y|X=x_i)\]熵越大,则随机变量的不确定性越大。
2.2 条件熵
随机变量X给定的条件下,随机变量Y的条件熵H(Y|X)定义为:
\[H(Y|X) = \sum_{i=1}^{n}p_i H(Y|X=x_i)\]其中,$p_i = P(X = x_i)$ 。
2.3 信息增益
信息增益表示的是:得知特征X的信息而使得类Y的信息的不确定性减少的程度。 具体定义如下: 特征A对训练数据集D的信息增益g(D,A)定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
\[g(D,A)=H(D)-H(D|A)\]一般地,熵H(Y)与条件熵H(Y|X)之差称为互信息(mutual information).
3. 特征选择
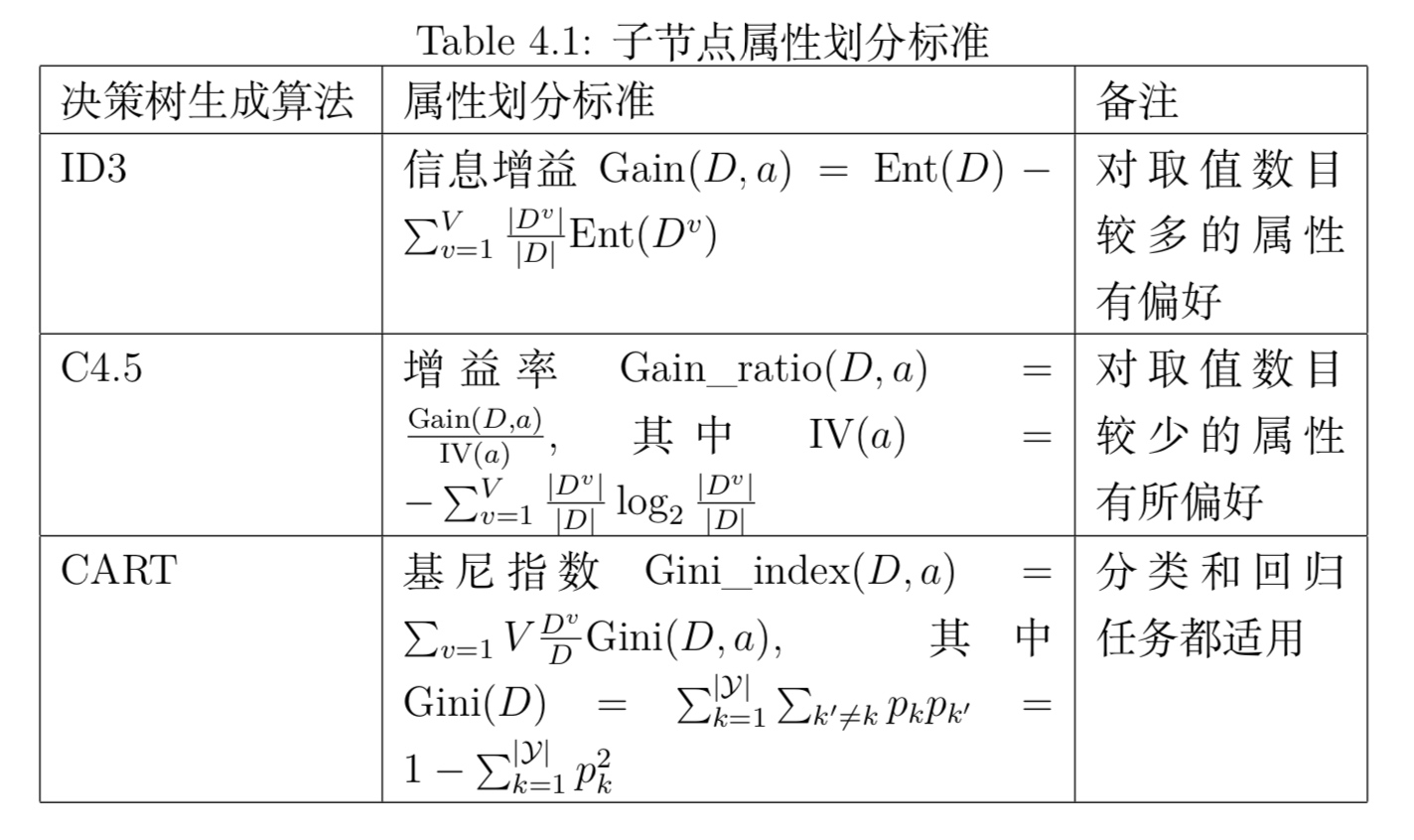
3.1 ID3决策树生成算法
- 总信息墒
$D$为样本集合,$\mid y\mid $为样本集合中样本的类别标记种类个数(分类器输出值),$p_i(x)$为样本集合中第$i$类样本的数量占比。则该样本集合的信息墒为:
\[H(D) = -\sum_i^{\mid y\mid } p_i(x)\cdot log(p_i(x))\]- a属性的信息墒(条件熵)
$a$为某一属性,$V$为该属性的可能取值,$D^v$为该属性值取值为$v$的样本组成的样本集合:
\[H(D, a) = \sum_v^{\mid V\mid }\cfrac{\mid D^v\mid }{\mid D\mid }H(D^v)\]其实, $H(D, a)$ 可以看作是条件墒 0.0~~~ $H(D, a)=H(D\mid x=v)$
- a属性的信息增益
- 信息增益原则会偏向于取值种类多的属性
由信息增益公式可知,当该属性的取值 $\mid V\mid $ 比较大时,例如每个取值对应一个样本,此时总信息墒为0,信息增益最大,但这样的决策树不具有泛化能力,无法应用。
熵表示的是数据中包含的信息量大小。熵越小,数据的纯度越高,也就是说数据越趋于一致,这是我们希望的划分之后每个子节点的样子。
信息增益 = 划分前熵 - 划分后熵。信息增益越大,则意味着使用属性a来进行划分所获得的 “纯度提升” 越大 。也就是说,用属性a来划分训练集,得到的结果中纯度比较高。
ID3的缺点:
- 只能处理分类属性的数据,不能处理连续的数据
- 划分过程会由于子集规模过小而造成统计特征不充分而停止
- ID3在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息
- 没有考虑过拟合的问题
- 对缺失值的情况没有考虑
3.2 C4.5决策树生成算法
C4.5克服了ID3仅仅能够处理离散属性的分类问题,以及信息增益偏向选择值较多特征的问题,使用信息增益比来选择特征,同时C4.5也引入了剪枝,以及对缺失值的处理, 这里着重说一下C4.5的以下这几个改进
- 处理连续属性:
将某个连续型特征的值按从小到大排序,比如为a1,a2,…,am,这样就有m-1个划分点,对这m-1个划分点进行信息增益计算,找到最好的特征点,其过程如同CART。
- 信息增益比:
信息增益趋向于选择值较多的特征的问题,这个很容易理解,信息熵衡量的是被分类后其混乱程度,如同聚类一样,同样数量的样本,聚的簇越多,簇内的样本当然就越紧密了(熵小),这里加了一个惩罚项,簇越多,值越大(是在同等情况下),公式如下:
- 信息增益率
定义:属性a的固有属性
\[IV(a)=-\sum_v^{\mid V\mid }\cfrac{\mid D^v\mid }{\mid D\mid }log\cfrac{\mid D^v\mid }{\mid D\mid }\]固有属性的定义类似于样本集合对不同取值的墒定义,当取值$\mid V \mid$变大后,$IV(a)$会变大,从而$Gain_ratio(D,a)$变小
- 信息增益率原则会偏向于取值种类少的属性
鉴于此,C4.5算法不是直接选择信息增益率最大的作为候选属性,而是用 启发式 先选择信息增益top50%的属性作为候选属性,再在其中选择信息增益率最高的属性作为最终划分属性。
决策树C4.5算法的不足
- 决策树非常容易过拟合,但剪枝的算法有很多种,C4.5的剪枝策略有优化的空间,一般剪枝有两种思路,一种是预剪枝,即在生成决策树的时候就决定是否剪枝,另一种是后剪枝,即先生成决策树,再通过交叉验证来剪枝(CART中的剪枝就是采用后剪枝+交叉验证)
- C4.5生成的是多叉树,即一个父节点可以有多个节点,而计算机中一般来说二叉树模型比多叉数运算高效
- C4.5只能用于分类
- C4.5分裂策略使用了熵模型,里面有大量耗时的对数运算,如果是连续值,还有大量的排序运算
3.3 CART决策树生成算法
CART与ID3,C4.5不同之处在于CART生成的树必须是二叉树,其全称是分类与回归树(classification and regression tree),既可以用于分类问题,又可以用于回归问题。 CART对C4.5进行了改进,其分类模型对比于C4.5: 其中在分裂策略上,C4.5使用熵模型,涉及大量的对数运算,而CART分类树算法使用基尼指数代替信息增益比,基尼系数代表了模型的纯度,基尼指数越小,模型越纯净。
- 基尼不纯度Gini impurity
基尼不纯度不同于基尼系数的概念,基尼不纯度反映了数据集$D$的纯度。表示从集合中任选两个样本其类别标记不一致的概率。Gini impurity越小,数据集$D$纯度越高。
\[\begin{equation} Gini(D)=\sum_k^{\mid y\mid }\sum_{k^{'}, k\neq k^{'}}^{\mid y\mid }p(k)\cdot p(k^{'}) \\ = \sum_k^{\mid y\mid }1-p^2(k) \end{equation}\]属性$a$的基尼不纯度定义为:
\[\begin{equation} Gini\_impurity(D,a)=\sum_v^{\mid V\mid }\cfrac{\mid D^v\mid }{\mid D\mid }Gini(D^v) \end{equation}\]在树的构建上,除了度量方式使用基尼指数外,与C4.5最大的区别就是CART使用二叉树,对于连续特征来说是一样的,但是对于离散特征而言就不同,比如被选中的特征A有三个类别A1,A2,A3,C4.5会在该节点下分裂为三个子树,但是CART采用的是不停的二分,比如上面的例子,CART会考虑将A分为{A1}和{A2,A3},{A1,A2}和{A3},{A1,A3}三种情况,然后分别对这三种情况找出基尼系数最小的组合来建立二叉树
4. 剪枝处理
剪枝(pruning)是决策树学习算法防止过拟合的重要手段。决策树剪枝的方式有预剪枝(prepruning)和后剪枝(post-pruning)。
- 预剪枝
预剪枝在决策树生成过程中进行,后剪枝在决策树生成完后进行。预剪枝基于“贪心”的本质,过程中某些分支虽然不会提高泛化能力,但在此基础上的后续分支很可能导致性能显著提高,可能产生欠拟合风险。
- 后剪枝
后剪枝相比预剪枝通常保留了更多的分支,一般情况下后剪枝欠拟合的风险很小,泛化能力优于预剪枝,但后剪枝需要在决策树生成之后自底向上逐一考察,训练时间更久。
- 评价
那么怎么来判断是否带来泛化性能的提升呢?最简单的就是留出法,即预留一部分数据作为验证集来进行性能评估
决策树的损失函数如下:
\[C_{\alpha}(T)=\sum_{t=1}^{|T|}N_tH_t(T)+\alpha|T|\\ H_t(T)=-\sum_k\frac{N_{tk}}{N_t}log\frac{N_{tk}}{N_t}\]其中树T的叶子节点个数为 $T_0$,t是树T的叶子节点,该叶节点有 $N_t$ 个样本点,其中k类样本点有 $N_{tk}$ 个,k=1,2,..,K,$H_t(T)$ 为叶节点t上的经验熵,$\alpha>=0$ 为参数
剪枝过程如下:
- 从生成算法的决策树 $T_0$ 底端开始不断剪枝,直到 $T_0$ 的根节点,形成一个子树序列 ${T_0,T_1,…,T_n}$
- 具体过程:对于固定的$\alpha$,一定存在使损失函数最小的子树,将其表示为 $T_{\alpha}$,也就是说不断的增加 $\alpha$,就会得到一系列的最优子树,直到 $\alpha$ 大到根节点组成的单节点树最优为止[详见统计学习方法]
- 通过交叉验证法在独立的数据集上对子序列进行测试,从中选择最优子树
5. 总结
优点:
- 简单直观
- 基本不需要预处理,不需要提前归一化
- 使用决策树预测的代价是 $O(log_2m)$
- 既可以处理离散值,也可以处理连续值
- 可以处理多维度输出的分类问题
- 可以通过交叉验证来选择模型,提高模型的泛化能力
缺点:
- 非常容易过拟合[剪枝]
- 受样本点的影响比较大[通过集成学习]
- 容易陷入局部最优[通过集成学习]
- 比较复杂的关系决策树学习不到,比如异或[使用神经网络]
- 样本不平衡会严重影响决策树生成[可以通过调节样本权重]
参考
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!