论文
Two-Level Transformer and Auxiliary Coherence Modeling for Improved Text Segmentation
0. 为什么要读这篇文章
最近有一个作文切题度任务,希望能借助这篇论文的思想,先使用本文双层Transformer的思想进行文本话题分割,然后再利用每个话题与作文题目介绍进行相似度对比,得出作文切题度。
1. 简介
文本的连贯性与文本的分割具有本质上的紧密联系,在分割后,同一部分的文本之间的连贯性应当强于不同部分的文本。如下图,共四种分割方式,其中T1均描述荷兰历史,T2均描述荷兰地理,T3,T4包含两个部分的句子。且T1的连贯性强于T3和T4,这说明第四句应该是一个新部分的起始。

依据语义连贯性解构长文本能够提升文本的可读性,有益于下游任务(检索、摘要、主题分类等)。而现存的文本分割方法都仅仅隐式的使用连贯性这项特征。
本文提出的监督模型使用双层Transformer网络编码句子序列,除了以预测分割结果作为目标以外,还对连贯性进行建模并应用在训练过程中。迫使模型预测连贯性更强的文本段落作为分割结果。进一步,文章提出的模型能够实现零样本语言迁移,其使用英文维基百科训练的模型能够在其他语言上获得较好的分割效果。
2. 连贯性感知双层Transformer模型
下图2就是这个CATS(Coherence-Aware Two-Level Transformer for Text Segmentation)模型
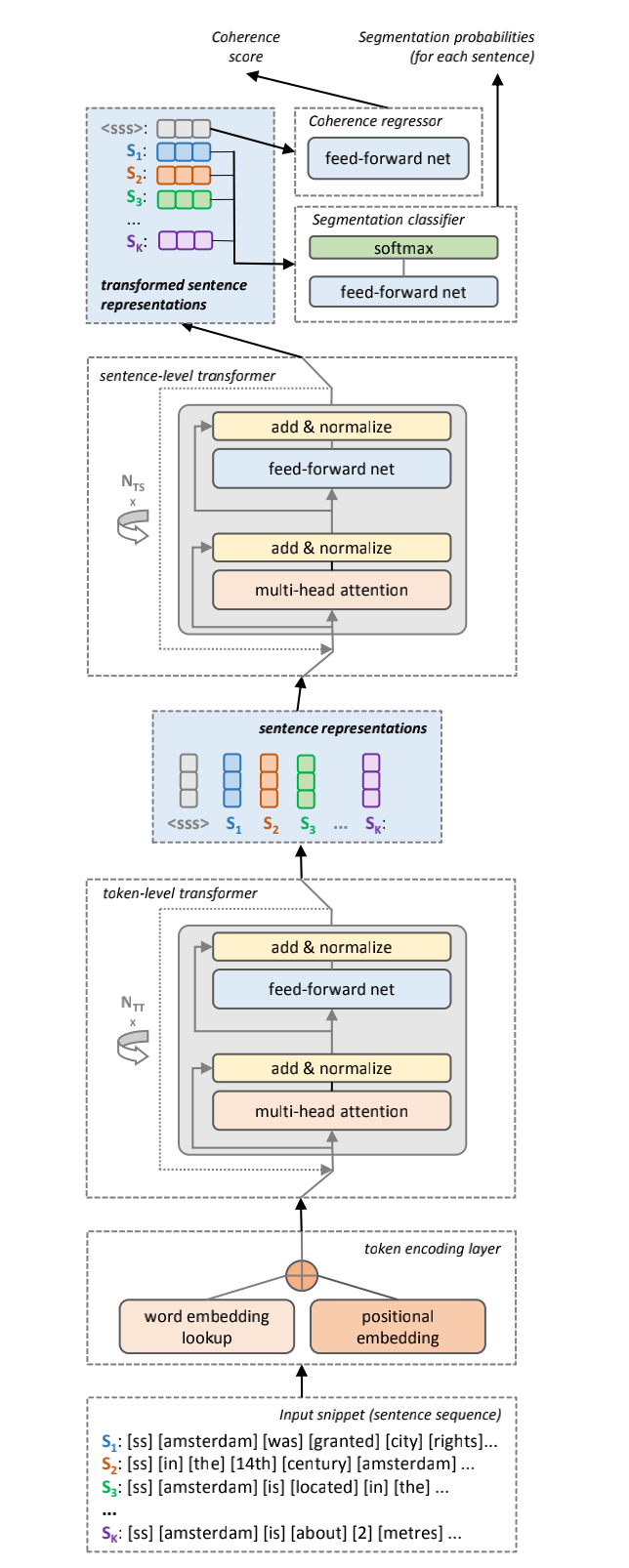
模型接收定长句子序列作为输入,字符编码由预训练词嵌入和位置嵌入连接得到。句子序列首先通过字符级Transformer得到句子表示,再经句子级Transformer强化上下文信息。编码器输出经过一前馈二分类器对各句进行分类。另将编码后的句子序列输入另一前馈网络获取一个连贯性分数。
获取位置嵌入的方法:Transformer 中的 positional embedding
2.1 以Transformer为基础的文本分割
选取分层结构的原因在于,某个句子属于哪一部分不单取决于其内容,还取决于其所处的上下文语境。选取Transformer则是因为该结构近期在NLP领域中的广泛应用和优于传统循环网络的优越性。
2.1.1 句子编码
句子序列:![]() 句子数 :K
句子数 :K
句子:![]() 句长:T
句长:T
句首添加特殊标识符 $t_0^i\ =\ [ss]$ 用于在经过低层后获取句子的表示
$t_i$ 由预训练词嵌入和位置嵌入组合而成, ${\rm Transform}_T$ 表示一层Transformer,则对于第一层,有
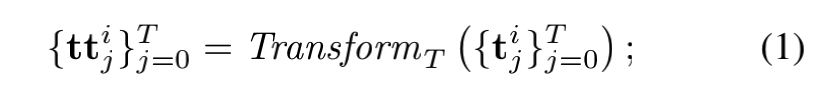
取结果序列首位作为句子表示 ![]()
2.1.2 句子置于上下文语境中
对于第二层
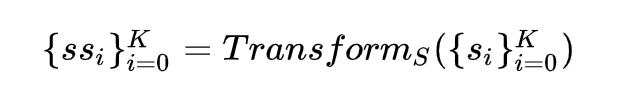
同理,取首位 ${\rm SS}^0$ 作为该句子序列 ![]() 的表示
的表示
2.1.3 文本分割分类
编码了上下文信息的句子表示进入分类器
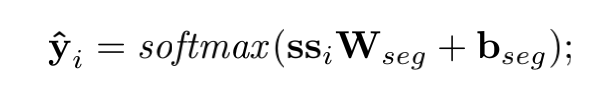
其中真实标签 ![]() ,使用负对数函数计算分类损失
,使用负对数函数计算分类损失
使用负的似然估计作为损失函数在所有句子上进行训练
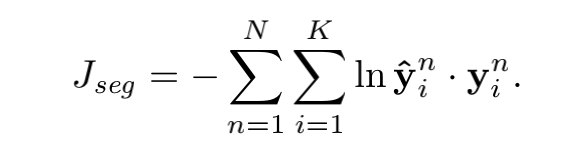
2.2 附加连贯性模型
对原文中的正确分割结果 ![]() 进行了破坏,得到反例
进行了破坏,得到反例 ![]() ,破坏的方法为1)随机打乱句子顺序,2)用其他分段的句子随机替换本分段中的句子
,破坏的方法为1)随机打乱句子顺序,2)用其他分段的句子随机替换本分段中的句子
将正确序列和错误序列的表示成对进行回归运算,有
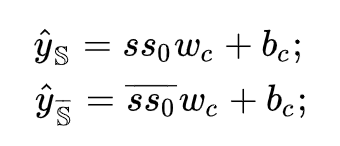
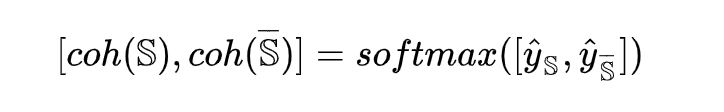
为了迫使模型预测出更具备连贯性的分割结果,定义损失函数如下,其中 ![]() 为正确序列与错误序列连贯性分数之差的下界
为正确序列与错误序列连贯性分数之差的下界
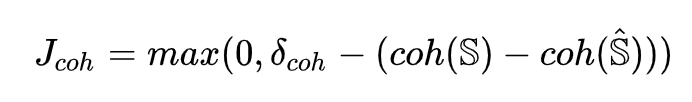
2.3 训练与预测
在训练过程中,使用长度为K的滑窗,以K/2为步长进行取样。
预测过程以1为步长进行取样,对于所有包含某句子S的序列 ![]() ,求其预测值的均值,
,求其预测值的均值,
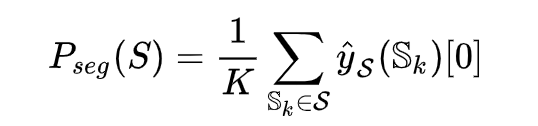
若 ![]() 大于某预设门限值(EducationalTestingService的代码中这个阈值是0.3),则认为该句是一个部分的起始句。
大于某预设门限值(EducationalTestingService的代码中这个阈值是0.3),则认为该句是一个部分的起始句。
2.4 利用跨语言词嵌入实现零样本语言迁移
跨语言词嵌入的最终目标是学习到一个可以在所有语言中共享的嵌入空间,使得我们可以在任何语言上进行模型的学习,同时获得到在其他任何语言上进行预测的能力。
鉴于本文提出的模型并未使用到特异性的语言特征,因此适合于使用跨语言词嵌入空间实现语言迁移,给定目标语言的词嵌入空间,即可在无该种语言训练样例的情况下进行文本分割
3. 实验部分
主要数据集:WIKI-727K Corpus、Standard Test Corpora、以及少部分非英语数据
评价指标: $P^k$ 分数,即任取一段由k各句子组成的序列,判断该序列的首句和尾句是否处于不同分段中,该分值越大,代表分割的效果越差。实验过程中,k取正确段落平均句子数的一半。
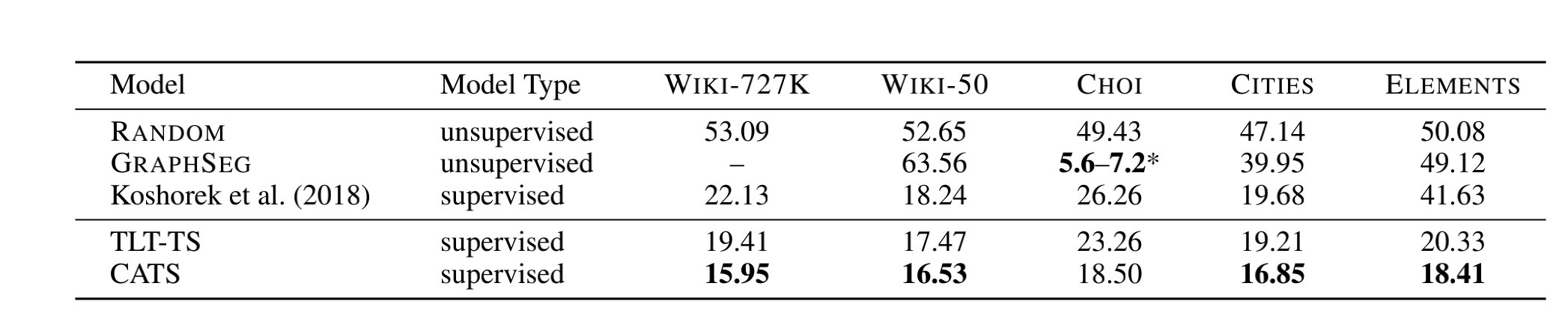
对比基线模型:1)有监督文本分割模型Koshorek et al. (2018) 2)无监督文本分割模型 GRAPHSEG 3)按比例随机给予正标签的RANDOM测试,为 $P^k$ 提供上界
消融实验:对比了有无显式连贯性建模的模型CATS(有)和TLT-TS(无)
3.1 结果分析
1.本文所提出的以Transformer作为基本结构的模型在各个数据上的指标表现均优于以循环神经网络作为基本结构的监督模型
2.具有显式连贯性辅助建模的模型表现优于隐式考虑连贯性的基本模型
3.特别的,在CHOI数据集上,无监督基线模型的表现大幅优于其他模型,原因是该数据集中的语料为人工合成,其在同一分割段落中的句子中倾向于词汇和语义的重叠,故对于直接通过重叠特征来进行分割的无监督模型较有优势。
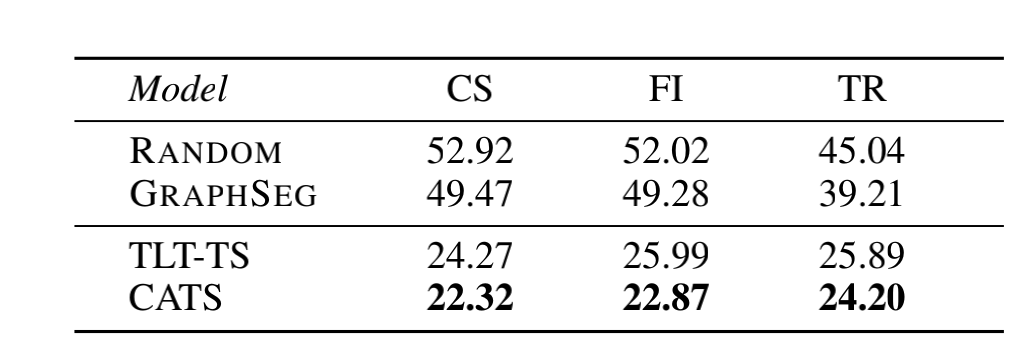
3.2. 语言迁移
结果表明,具有辅助连贯性建模的模型CATS的表现优于其余模型。尽管相对于在英文数据集上的结果,语言迁移仍导致了性能的部分下降,但该结果还是给缺乏大量正确分割结果的数据集的处理提供了可能。
4. 结论
现存文本分割模型多依据相邻句子之间词汇或词义的重复率来表征文段的连贯性,以此作为分割的依据。本文提出由两层Transformer构成的监督模型,低层编码句子,高层编码句子序列。在两项任务上进行训练,分别为 1)预测句子分段标签 2)对比正确分段和错误分段的连贯性。该模型在多个文本分割数据集上取得sota(state-of-the-art,指该项研究任务中,最好/最先进的模型),且能够实现向其他语言的零样本迁移。未来或可在负样本构建的过程上进行改进。
代码实现
Two Level Transformer for text seg Github EducationalTestingService/CATS
参考
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!