头条面试题
1.hive常用函数
1.1 行转列和列转行
- 表1:cityInfo
| cityname | regionname |
|---|---|
| 上海 | 四川北路 |
| 上海 | 虹梅路 |
| 上海 | 音乐学院 |
| 上海 | 徐家汇 |
| 北京 | 东四 |
| 北京 | 复兴门 |
- 表2:cityInfoSet
| cityname | regionname |
|---|---|
| 上海 | 四川北路,虹梅路,音乐学院,徐家汇 |
| 北京 | 复兴门,东四 |
表1和表2的结构如上所示。如何在 hive 中使用 Hql 语句对表1和表2进行互相转化呢?
行转列
表1=>表2 可以使用 hive 的内置函数 concat_ws() 和 collect_set()进行转换:
执行代码如下所示:
select cityname,concat_ws(',',collect_set(regionname)) as address_set from cityInfo group by cityname;
列转行
表2=>表1 可以使用 hive 的内置函数 explode()进行转化。代码如下:
select cityname, region from cityInfoSet lateral view explode(split(address_set, ',')) a
mysql行转列
表3
| airport_code |
|---|
| SZX |
| _BJQ |
| _IOQ |
| _OSQ |
| _SZQ |
表4
| airport_code |
|---|
| CGQ,_CRT,_CCT,_CET |
表3=>表4 可以使用 mysql 的内置函数 group_concat()进行转换:
执行代码如下所示:
select group_concat(distinct(airport_code) SEPARATOR ",") from fixed_product where city='cc' and airport_code!='';
2.Hive常用的窗口函数
https://blog.csdn.net/qq_26937525/article/details/54925827
3.两个单向链表查找交叉项
https://blog.csdn.net/hsz_zl/article/details/53363482
4.shuffle过程
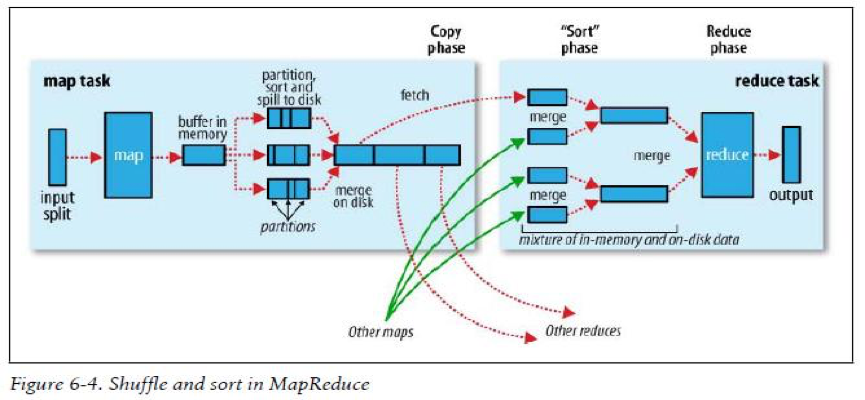
4.1 map side
- 在写入磁盘之前,会先写入环形缓冲区(circular memory buffer),默认100M(mapreduce.task.io.sort.mb可修改),当缓冲区内容达到80M(mapre duce.map.sort.spill.percent可修改),缓冲区内容会被溢写到磁盘,形成一个spill file文件
- 分区:在写入磁盘之前,会先进性分区(partition),而partition的数量是由reducer的数量决定的
- 排序:在每一个partition中,都会有一个sort by key
- combiner:如果有combiner function,在sort之后会执行combiner
- merge:数个spill files会合并(merge)成一个分过区的排过序的文件
- compress压缩the map output
mapred-default.xml
mapreduce.task.io.sort.factor 一次性合并小文件的数量 默认10个
mapreduce.map.output.compress 启用压缩,默认是false
mapreduce.map.output.compress.codec org.apache.hadoop.io.compress.DefaultCodec 默认使用的压缩算法
4.2 reduce side
- 解压缩:如果在map side 已经压缩过,在合并排序之前要先进行解压缩
- sort phase(merge)
- group phase:将相同key的value分到一组,形成一个集合
5.hadoop文件分块、map、redue个数的划分
hadoop默认配置块大小是64mb,现在有三个文件分别是1m、64m、129m在hadoop文件系统中会分成几块?
split分片有个判断逻辑,当剩余大小大于split大小的1.1倍时,才进行分片。129mb的分成64mb、65mb再分时小于64mb的1.1倍所以不会划分,所以总文件个数是4个:1mb,64mb,64mb,65mb。
6.线性回归使用条件
- 线性性:自变量与因变量是否呈直线关系。
- 误差项的独立性:不同的观测对应的误差项应该是相互独立的。
- 同方差性(homoscedasticity)。即误差项的方差应该是一样的。
- 正态性。要求误差项来自正态分布。
7.第三范式
- 第一范式(1NF):确保每列的原子性。
- 如果每列(或者每个属性)都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式.
- 例如:顾客表(姓名、编号、地址、……)其中”地址”列还可以细分为国家、省、市、区等。
- 第二范式(2NF):在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关。
- 如果一个关系满足第一范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式.
- 例如:订单表(订单编号、产品编号、定购日期、价格、……),”订单编号”为主键,”产品编号”和主键列没有直接的关系,即”产品编号”列不依赖于主键列,应删除该列。
- 第三范式(3NF):在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关.
- 如果一个关系满足第二范式,并且除了主键以外的其它列都不依赖于主键列,则满足第三范式.
- 为了理解第三范式,需要根据Armstrong公里之一定义传递依赖。假设A、B和C是关系R的三个属性,如果A-〉B且B-〉C,则从这些函数依赖中,可以得出A-〉C,如上所述,依赖A-〉C是传递依赖。
- 例如:订单表(订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列”订单编号”相关,再细看你会发现”顾客姓名”和”顾客编号”相关,”顾客编号”和”订单编号”又相关,最后经过传递依赖,”顾客姓名”也和”订单编号”相关。为了满足第三范式,应去掉”顾客姓名”列,放入客户表中。
8.mysql底层数据结构、索引、组合索引
参考mysql索引类型 https://www.cnblogs.com/luyucheng/p/6289714.html
9.新生代、老年代、永久代
java文件在新生代、老年代、永久代执行过程
参考:https://blog.csdn.net/qq_23835497/article/details/71696067
微博面试题
1.两个200g文件,两个字段join
2.一个2g的文件,200mb内存,排序
这是一个单机外部排序的典型题目。具体的方法就是先分块进行排序然后多路归并成输出文件。 参考:https://blog.csdn.net/michellechouu/article/details/47002393
3.二叉树,查找相加等于50的相邻节点
360面试题
1.hive sql如何解决数据倾斜
Reference:https://blog.csdn.net/u010670689/article/details/42920917
2.hive sql统计pv、uv
PV实现:
select date,hour,count(url) PV from yhd_part1 group by date,hour;
- 按照天和小时进行分区
- 结果:
| date | hour | pv |
|---|---|---|
| 20150828 | 18 | 64972 |
| 20150828 | 19 | 61162 |
UV实现:
select date,hour,count(distinct guid) UV from yhd_part1 group by date,hour;
-》结果:
| date | hour | uv | |———–|——-|——–| | 20150828 | 18 | 23938 | | 20150828 | 19 | 22330 |
快手面试题
1.删除字符串中的连续空格(只保留一个),O(n)时间复杂度,O(1)空间复杂度
Reference:https://blog.csdn.net/calmreason/article/details/8105874
2.手写多路归并
Reference:https://blog.csdn.net/u010367506/article/details/23565421 Reference:https://blog.csdn.net/wongson/article/details/49209903
腾讯面试题
1.有一个图,其中有环,怎么给他找出来
感觉使用邻接表和深度优先遍历可以实现 邻接表尾跟头一样就是个环就是个回路吧 Reference:https://wenku.baidu.com/view/4497a7f7aef8941ea76e059a.html
蚂蚁金服电话面试
1.kafka底层原理
Reference:https://blog.csdn.net/u013573133/article/details/48142677
2.java序列化,一个对象新增字段保证序列化不变
Reference:https://www.cnblogs.com/xdp-gacl/p/3777987.html
3.垃圾回收的策略,先创建的先删除怎么办
Reference:http://www.cnblogs.com/laoyangHJ/articles/java_gc.html
4.mysql索引底层存储结构,B-Tree为什么比红黑树快
Reference:https://www.cnblogs.com/boothsun/p/8970952.html
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!