1.Hadoop安装
1.1 安装homebrew
打开终端,输入命令,安装homebrew。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
1.2 安装Java
下一步特别需要安装Java,特别注意!!安装Java8,不要安装更高级的版本了,否则Hadoop Yarn中ResourceManager、NodeManager启动异常。由于使用brewhome默认安装的Java版本是11,所以需要指定安装Java8。
安装命令
brew tap caskroom/versionsbrew cask install java8
配置环境变量,vim修改 ~/.bash_profile
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_221.jdk/Contents/Home
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
配置生效
source ~/.bash_profile
1.3 配置ssh
打开系统偏好设置->共享里的共享配置。
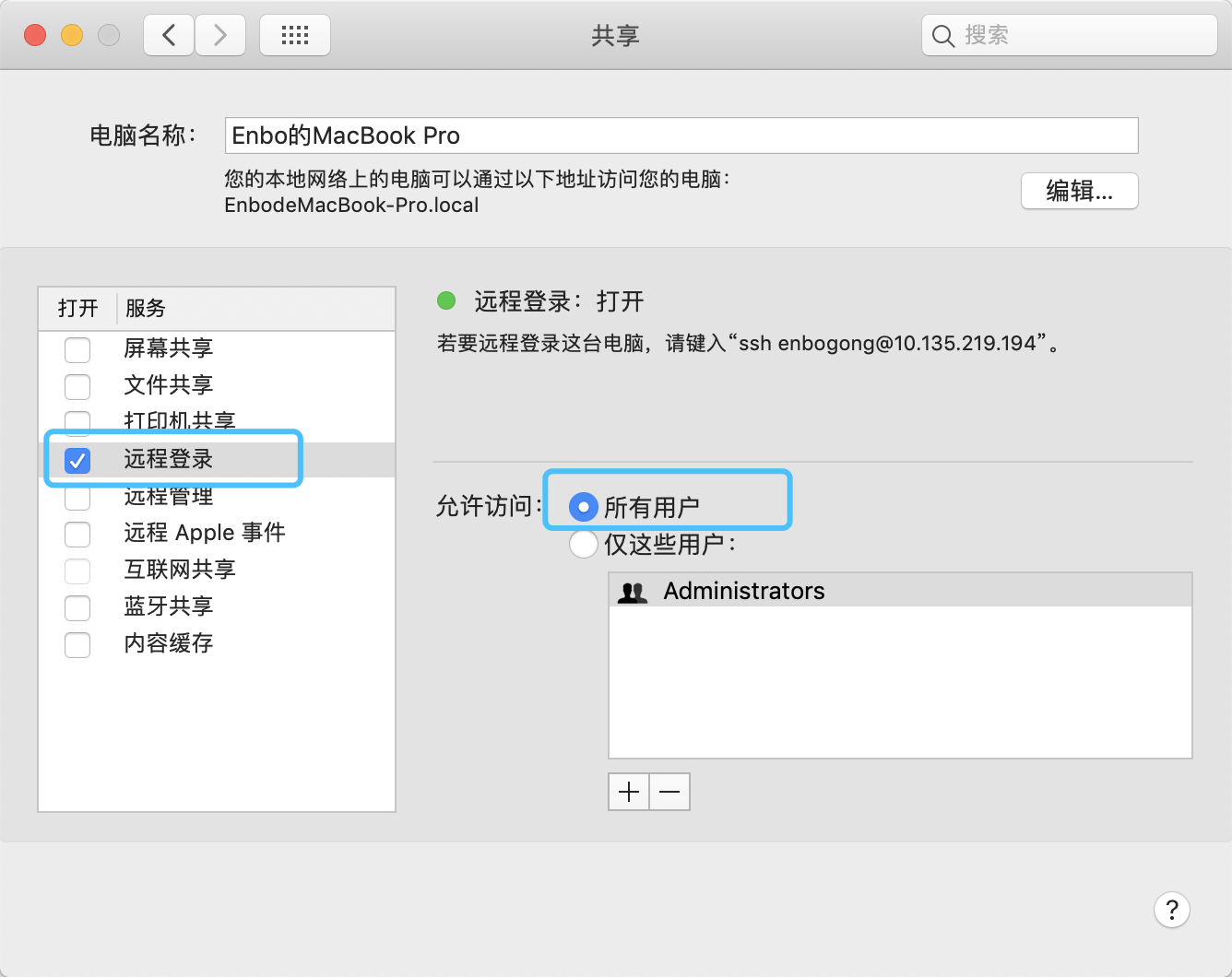
生成公钥,配置免密登录
ssh-keygen -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
配置完后,检查是否可以免密登录
ssh localhost
1.4 安装Hadoop
brew install haoop
1.5 配置伪分布式
进入hadoop文件夹中,修改相关的配置
cd /usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop
修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Cellar/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/Cellar/hadoop/3.1.2/libexec/etc/hadoop:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/common/lib/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/common/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/hdfs:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/hdfs/lib/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/hdfs/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/mapreduce/lib/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/mapreduce/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/yarn:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/yarn/lib/*:/usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/yarn/*</value>
</property>
</configuration>
修改hadoop-env.sh
在export JAVA_HOME的位置添加JAVA路径
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_221.jdk/Contents/Home
还需要格式化HDFS,在/usr/local/Cellar/hadoop/3.1.2/libexec/bin路径下执行
hdfs namenode -format
1.6 配置Hadoop环境变量
配置环境变量,vim修改 ~/.bash_profile
HADOOP_HOME=/usr/local/Cellar/hadoop/3.1.2/libexec
export PATH=$M2:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
1.7 启动Hadoop
在/usr/local/Cellar/hadoop/3.1.2/libexec/sbin路径下,执行
./start-all.sh
然后jps看java进程
jps
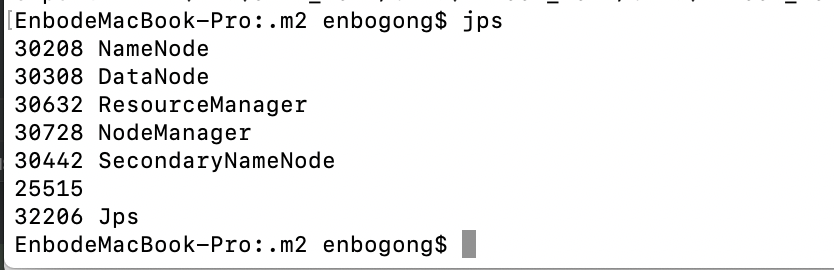
如果出现ResourceManager、SecondaryNameNode、NameNode、NodeManager、DataNode这五个进程说明Hadoop可以正常使用了。
1.8 运行mareduce程序遇到的问题
运行自带的wordcount过程中遇到错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster问题,通过在yarn-site.xml中添加yarn.application.classpath解决了
Reference:https://blog.csdn.net/hongxiao2016/article/details/88919176
1.9 运行wordcount测试
自己创建一个wordcount文件,文件名data
cat dog big hat
head hat teacher cat
dog cat
将data上传到hdfs
hadoop fs -mkdir /wordcount/
hadoop fs -put /wordcount/data data
进入hadoop-mapreduce-examples-3.1.2.jar所在的目录
cd /usr/local/Cellar/hadoop/3.1.2/libexec/share/hadoop/mapreduce
运行wordcount程序
hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /wordcount/data /wordcount/out
等待执行完毕查看运行结果
hadoop fs -cat /wordcount/out/part-r-00000
big 1
cat 3
dog 2
hat 2
head 1
teacher 1
1.10 常用监控界面
hdfs界面:http://localhost:9870/dfshealth.html#tab-overview
yarn界面:http://localhost:8088/cluster
2.Spark的安装
2.1 Scala安装
brew install scala
配置环境变量
export SCALA_HOME=/usr/local/Cellar/scala/2.13.0
export PATH=$PATH:$SCALA_HOME/bin
配置生效
source ~/.bash_profile
2.2 Spark安装
brew install apache-spark
配置环境变量
export SPARK_PATH=/usr/local/Cellar/apache-spark/2.4.3
export PATH="$SPARK_PATH/bin:$PATH"
配置生效
source ~/.bash_profile
Spark安装更简单,可以通过执行一个例子检验是否正确安装。
run-example SparkPi
运行结果:

3.Kafka的安装
3.1 zookeeper安装
brew install zookeeper
3.2 kafka安装
brew install kafka
4. 总结
由于brewhome的存在,比之前自己手动下包安装方便太多了。基本按照这个流程没有问题,如果出错的话,还需要具体问题具体分析。
5参考文献
Reference:https://www.jianshu.com/p/fdf3dffb6641
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!