1.介绍
分布式最难的2个问题:
- Exactly Once Message processing,
- 保证消息处理顺序
在业务场景中经常要保证端到端数据的一致性,既不能丢数也不能重复,下面我们来看一下Spark Streaming,
如何实现Exactly Once端到端性语义,
2. 实时计算语义
2.1 At most once(最多一次)
这本质上是一种“尽力而为”的方式。数据或事件被保证在应用中最多被所有算子处理一次。这意味着如果在应用处理完之前数据丢失,那么没有额外的重试或重新发送。

2.2 At least once(最少一次)
应用中的所有算子保证数据或事件被至少处理一次。这意味着如果在应用处理完之前有事件丢失,该事件将会被从数据源重放或重新发送。因为它可以被重新发送,一个事件有时可以被处理多次,即至少一次。
2.3 Exactly once(恰好一次)
每条数据记录正好被处理一次。没有数据丢失,也没有重复的数据处理。这一点是3个语义里要求最高的。
3. 一些术语
3.1 端到端一致性end to end Consistency
一致性其实就是业务正确性, 在不同的业务场景有不同的意思, 在”流系统中间件”这个业务领域, 端到端的一致性就代表Exact once msg processing, 一个消息只被处理一次,造成一次效果。
3.2 幂等Idempotent
一个相同的操作, 无论重复多少次, 造成的效果都和只操作一次相等; 比如更新一个keyValue, 无论你update多少次, 只要key和value不变,那么效果是一样的; 再比如更新计数器处理一次消息就计数器+1, 这个操作本身不幂等, 同一个消息被中间件重”发+收”两次就会造成计数器统计两次; 而如果我们的消息有id, 那么更新计数器的逻辑修改为, 把处理过的消息的id全记录起来, 接到消息先查重, 然后才更新计数器, 那么这个”更新计数器的逻辑”就变成幂等操作了。
3.3 确定性计算deterministic
和幂等有些类似, 不过是针对一个计算; 相同的input必得到相同的output, 则是一个确定性(deterministic); 比如从一个msg里计算出一个key和一个value, 如果对同一个消息运算无数次得到的key和value都相同, 那么这个计算就是deterministic的, 而如果key里加上一个当前的时钟的字符串表示, 那么这个计算就不是确定性的, 因为如果重新计算一次这个msg, 得到的是完全不同的key;
注意1: 非确定性计算一般会导致不幂等的操作, 比如我们如果要把上边例子里的keyvalue存在数据库里, 重复处理多少次同一个msg, 我们就会重复的插入多少条数据(因为key里的时间戳字符串不同);
注意2: 非确定性计算并非必然导致不幂等的操作,比如这个时间戳没有添加在key里而是添加在value里, 且key总是相同的, 那么这个计算还是”非确定性”计算; 但是当我们存数据的时候先查重才存keyvalue, 那么无论我们重复处理多少次同一个msg, 我们也只会成功存入第一个keyValue, 之后的keyValue都会被过滤掉;
支持非确定业务计算的同时, 还能在容错的情况下达成端到端一致性, 是流系统的大难题, 甚至我们今天会提到的几个state of art的流系统都未必完全支持; (好吧Spark说的就是你)
4. 实现exactly once
4.1 At-least-once+ 幂等性操作
所有流式中间件如kafka都支持至少一次提交语义,配合幂等Sink可以做到不使用事务来保证exactly-once,下游可以避免上游重算导致的数据重复。
4.1.1. 输出端使用唯一id实现幂等
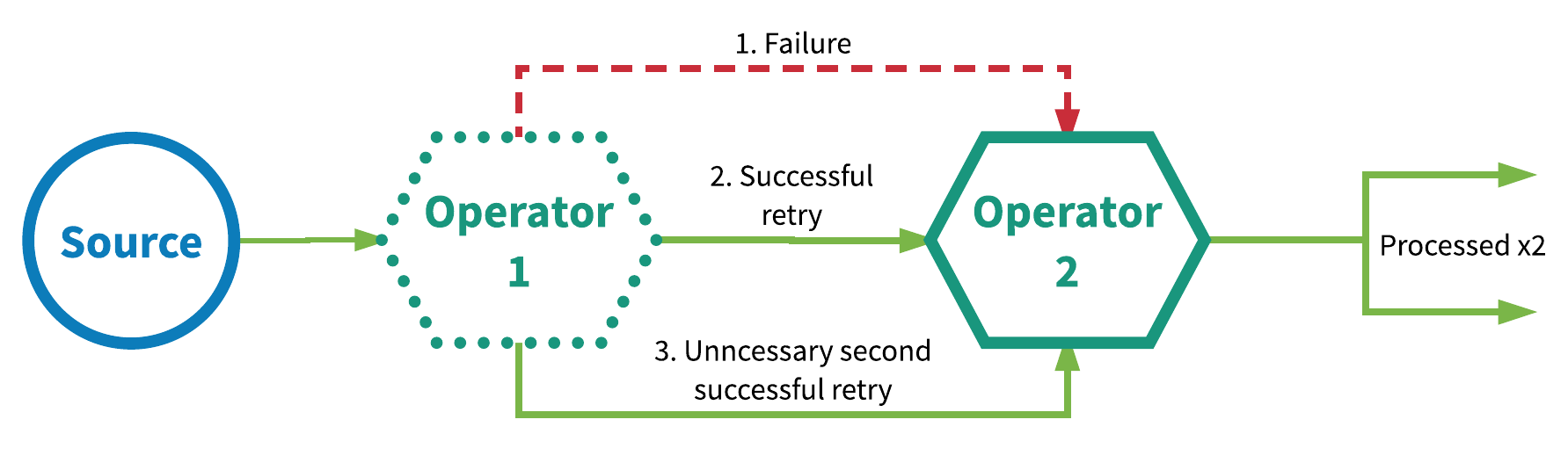
下游用于应对由于超时等原因导致的重复数据发送问题,一般解决方案为使用唯一id,上游在收到id的ack之后才继续发送id+1,否则无限重试。Google MillWheel做出了一个很有意思的选择,发送端完全不维护sequenceId,而是为每一个发出的message生成一个全局唯一的id,下游则需要记住”所有”见过的id来去重,但是这样会造成大量查询io和存储cost,所以需要另外的方案来解决性能和下游没有无限的存储所以”不可能记住所有id”的问题。
4.1.2. 利用ack
当逻辑接收端不固定, 比如发送端要根据计算出来的outputA的某key字段把不同的key发送给负责不同key range(也就是partition)的多个”下游计算接收端”。
只需要一个sequenceId就可以实现接收端的消息去重。接收端和发送端各维护一个partition level的sequenceId即可。这样当发送端收到当前message sequenceId(假设为n)的Ack才发下一个sequenceId为n+1的信息,否则就无限重试。而接收端则根据收到的消息的id是不是已经处理过的最大id+1来判断是这是不是下一个message。
缺点:无法支持非确定性计算( non-deterministic )
4.2 事务实现
4.2.1. 没有Shuffle(offset分布式提交)
各个节点内各自提交Offset和结果数据,出现故障单独回滚重试即可。
4.2.2. 包含Shuffle(退化为单节点事务)
Offset和partition绑定,而Shuffle会导致多个Partition数据被彼此互相打乱,需要拉取到单一节点统一提交。保证一个批次内所有数据和所有Offset在一个事务内提交。
缺点:该操作使分布式计算退化为单节点计算,单节点事务的提交可能出现提交缓慢并导致数据处理积压
7.参考
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!